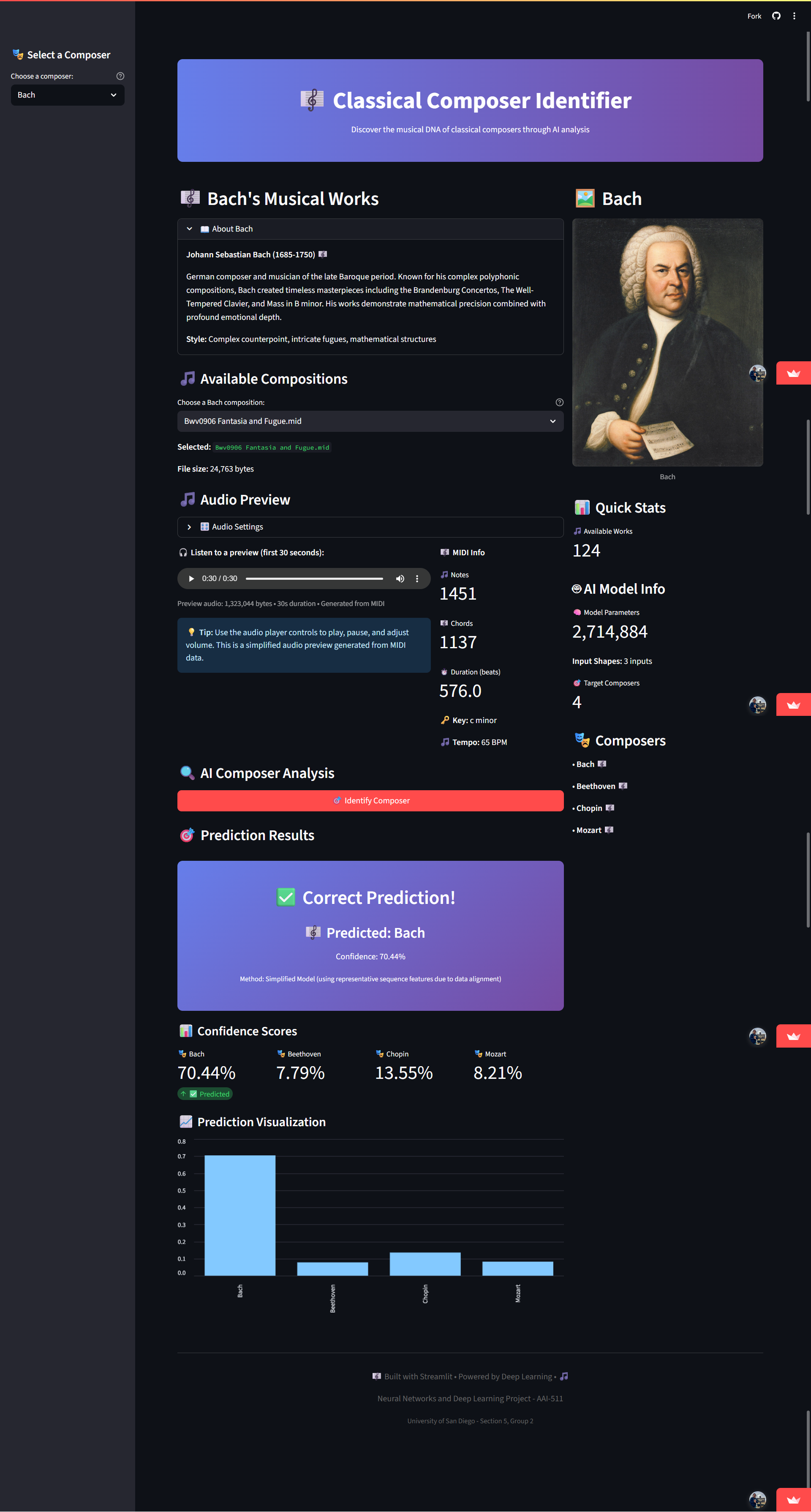
University of San Diego AAI-511: Neural Networks and Deep Learning
Professor: Rod Albuyeh
Section: 5
Group: 2
Contributors:
- Ashley Moore
- Kevin Pooler
- Swapnil Patil
August, 2025
Project Overview¶
Classical music represents one of humanity's most sophisticated artistic achievements, with master composers like Bach, Beethoven, Chopin, and Mozart developing distinctive musical signatures that have influenced centuries of musical evolution. Each composer possesses unique characteristics in their compositional style from Bach's intricate counterpoint and mathematical precision to Chopin's romantic expressiveness and innovative harmonies. These stylistic fingerprints, embedded within the very fabric of their musical works, present an fascinating opportunity for artificial intelligence to learn and recognize patterns that define musical authorship.
The Challenge¶
Traditional musicological analysis relies heavily on human expertise to identify compositional styles, requiring years of specialized training to distinguish between composers based on harmonic progressions, melodic patterns, rhythmic structures, and formal organization. However, with the advent of digital music representation and deep learning technologies, we can now approach this problem computationally, extracting and analyzing musical features at a scale and precision impossible for human analysis alone.
Approach¶
This project introduces a novel hybrid deep learning architecture that combines the sequential pattern recognition capabilities of Long Short-Term Memory (LSTM) networks with the spatial feature extraction power of Convolutional Neural Networks (CNNs) to automatically classify musical compositions by their composers. Our methodology integrates three distinct feature extraction approaches:
- Musical Features: Traditional music theory elements including pitch distributions, harmonic progressions, tempo variations, and rhythmic patterns
- Harmonic Features: Advanced harmonic analysis capturing chord progressions, key relationships, and tonal structures
- Sequential Features: Time-series representation of musical events, preserving the temporal relationships crucial to compositional style
Innovation and Impact¶
By processing MIDI files through sophisticated feature engineering and applying state-of-the-art neural network architectures, this system demonstrates how machine learning can complement musicological research, offering new insights into compositional analysis while providing practical applications for music education, digital humanities, and automated music cataloging.
This work represents a significant step toward understanding how artificial intelligence can capture and interpret the subtle nuances that define artistic style, with implications extending beyond music to other domains of creative expression and cultural analysis.
Objective¶
Develop a hybrid LSTM-CNN deep learning model to classify classical music compositions by composer (Bach, Beethoven, Chopin, Mozart) using multi-modal feature extraction from MIDI files.
Key Components¶
- Feature Engineering: Musical, harmonic, and sequential feature extraction
- Architecture: Hybrid LSTM-CNN fusion network for temporal and spatial pattern recognition
- Evaluation: Cross-validation with accuracy, precision, recall, and F1-score metrics
- Target: >85% classification accuracy with model interpretability analysis
Deliverables¶
- Multi-modal feature extraction pipeline
- Hybrid neural network architecture
- Trained composer classification model
- Performance evaluation and optimization results
The project will use a dataset consisting of musical scores from various composers.
https://www.kaggle.com/datasets/blanderbuss/midi-classic-music
The dataset contains the midi files of compositions from well-known classical composers like Bach, Beethoven, Chopin, and Mozart. The dataset should be labeled with the name of the composer for each score. Please only do your prediction only for below composers, therefore you need to select the required composers from the given dataset above.
- Bach
- Beethoven
- Chopin
- Mozart
%pip install -q -r requirements.txt
%load_ext autoreload
%autoreload 2
^C Note: you may need to restart the kernel to use updated packages. The autoreload extension is already loaded. To reload it, use: %reload_ext autoreload
[notice] A new release of pip is available: 25.1.1 -> 25.2 [notice] To update, run: python.exe -m pip install --upgrade pip
# Toggle the following flags to control the behavior of the notebook
EXTRACT_FEATURES = False
SAMPLING = False
SAMPLING_FILES_PER_COMPOSER = 20
# System and utility imports
import sys
import os
import time
import warnings
import pickle
import hashlib
from functools import lru_cache
from collections import Counter, defaultdict
from concurrent.futures import ThreadPoolExecutor, as_completed
from multiprocessing import cpu_count
from tqdm import tqdm
# Data processing libraries
import numpy as np
import pandas as pd
# Visualization libraries
import matplotlib.pyplot as plt
import seaborn as sns
from mpl_toolkits.mplot3d import Axes3D
# Music processing libraries
import music21
from music21 import (
converter, note, chord, roman, key, tempo, instrument,
interval, pitch, stream
)
import pypianoroll
import pretty_midi
import librosa
import librosa.display
# Deep learning libraries
import torch
import tensorflow as tf
# Add parent directory to path
warnings.filterwarnings('ignore')
sys.path.append(os.path.abspath(os.path.join(os.pardir, 'src')))
class EnvironmentSetup:
"""
Centralized environment configuration class for faster music classification.
Handles all environment setup including GPU configuration, reproducibility,
and optimization settings.
"""
def __init__(self):
self.random_seed = 42
self.optimal_workers = None
self.gpu_configured = False
self.cuda_available = False
self.config_summary = []
self.force_gpu = True # New flag to force GPU usage when available
self.cuda_device_id = 0 # Default CUDA device ID to use
self.color_pallete = "viridis"
def configure_environment(self):
"""Configure all environment settings for optimal performance and
reproducibility."""
# Configure reproducibility
self._configure_reproducibility()
# Configure GPU and memory settings
self._configure_gpu_and_memory()
# Configure CPU workers
self._configure_cpu_workers()
# Configure visualization settings
self._configure_visualization()
# Configure pandas settings
self._configure_pandas()
# Configure warnings
self._configure_warnings()
# Print final configuration summary
self._print_configuration_summary()
def _configure_reproducibility(self):
"""Set random seeds for reproducible results."""
np.random.seed(self.random_seed)
tf.random.set_seed(self.random_seed)
self.config_summary.append(f"Random seeds set to {self.random_seed} for reproducibility")
def _configure_gpu_and_memory(self):
"""Configure GPU settings and memory management for optimal performance."""
try:
# Check for CUDA availability first
self.cuda_available = torch.cuda.is_available()
if self.cuda_available:
cuda_version = torch.version.cuda
device_count = torch.cuda.device_count()
self.config_summary.append(f"CUDA is available (version: {cuda_version}, devices: {device_count})")
# Set CUDA device
if self.cuda_device_id < device_count:
torch.cuda.set_device(self.cuda_device_id)
self.config_summary.append(f"Set active CUDA device to: {torch.cuda.get_device_name(self.cuda_device_id)}")
# Set seeds for reproducibility
torch.cuda.manual_seed(self.random_seed)
torch.cuda.manual_seed_all(self.random_seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = True # Enable for improved performance with fixed input sizes
self.config_summary.append(f"CUDA random seed set to {self.random_seed}")
self.config_summary.append(f"CUDA deterministic mode: enabled")
self.config_summary.append(f"CUDA benchmark mode: enabled")
# Export CUDA device for other libraries
os.environ["CUDA_VISIBLE_DEVICES"] = str(self.cuda_device_id)
self.config_summary.append(f"Set CUDA_VISIBLE_DEVICES={self.cuda_device_id}")
else:
self.config_summary.append("CUDA is not available")
# Check for GPU availability in TensorFlow
gpus = tf.config.experimental.list_physical_devices('GPU')
if gpus:
self.config_summary.append(f"Found {len(gpus)} GPU(s)")
if self.force_gpu:
# Force TensorFlow to use GPU
tf.config.set_visible_devices(gpus, 'GPU')
self.config_summary.append("Forced TensorFlow to use GPU")
# Configure memory growth to prevent TensorFlow from allocating all GPU memory
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
self.config_summary.append(f"Configured memory growth for GPU: {gpu.name}")
# Set mixed precision for better performance on modern GPUs
tf.config.optimizer.set_jit(True) # Enable XLA compilation
policy = tf.keras.mixed_precision.Policy('mixed_float16')
tf.keras.mixed_precision.set_global_policy(policy)
self.config_summary.append("Enabled mixed precision training (float16)")
self.config_summary.append("Enabled XLA compilation for faster execution")
# Configure GPU device placement
tf.config.experimental.set_device_policy('explicit')
self.config_summary.append("Set explicit device placement policy")
self.gpu_configured = True
else:
self.config_summary.append("GPU available but not forced (force_gpu=False)")
else:
self.config_summary.append("No GPU found in TensorFlow. Using CPU for computation.")
# Configure CPU optimizations
tf.config.threading.set_intra_op_parallelism_threads(0) # Use all available cores
tf.config.threading.set_inter_op_parallelism_threads(0) # Use all available cores
self.config_summary.append("Configured CPU threading for optimal performance")
except Exception as e:
self.config_summary.append(f"Error configuring GPU: {e}")
self.config_summary.append("Falling back to default CPU configuration")
def set_cuda_device(self, device_id=0):
self.cuda_device_id = device_id
def toggle_force_gpu(self, force=True):
self.force_gpu = force
def _configure_cpu_workers(self):
"""Configure optimal number of CPU workers for parallel processing."""
# Set optimal number of workers based on CPU cores
self.optimal_workers = min(cpu_count(), 12) # Cap at 12 to avoid memory issues
# Make it globally accessible
globals()['OPTIMAL_WORKERS'] = self.optimal_workers
self.config_summary.append(f"Configured {self.optimal_workers} workers for parallel processing (CPU cores: {cpu_count()})")
def _configure_visualization(self):
"""Configure matplotlib and seaborn settings."""
sns.set(style='whitegrid')
plt.style.use('default')
plt.ioff() # Turn off interactive mode for better performance
self.config_summary.append("Visualization settings configured (seaborn whitegrid, matplotlib default)")
self.color_pallete = sns.color_palette("viridis")
def _configure_pandas(self):
"""Configure pandas display options."""
pd.set_option('display.max_columns', None)
pd.set_option('display.width', None)
pd.set_option('display.max_rows', 100)
self.config_summary.append("Pandas display options configured (max_columns=None, max_rows=100)")
def _configure_warnings(self):
"""Suppress unnecessary warnings."""
warnings.filterwarnings('ignore')
self.config_summary.append("Warning filters configured (suppressed for cleaner output)")
def _print_configuration_summary(self):
"""Print a summary of the current configuration."""
print("=" * 60)
print("ENVIRONMENT CONFIGURATION SUMMARY")
print("=" * 60)
for item in self.config_summary:
print(item)
print("\nCONFIGURATION DETAILS:")
print(f"Random Seed: {self.random_seed}")
print(f"CPU Workers: {self.optimal_workers}")
print(f"GPU Configured: {self.gpu_configured}")
print(f"CUDA Available: {self.cuda_available}")
print(f"Force GPU: {self.force_gpu}")
if self.cuda_available:
print(f"Active CUDA Device: {torch.cuda.get_device_name(self.cuda_device_id)}")
print(f"CUDA Memory Allocated: {torch.cuda.memory_allocated(self.cuda_device_id) / 1024**2:.2f} MB")
print(f"CUDA Memory Reserved: {torch.cuda.memory_reserved(self.cuda_device_id) / 1024**2:.2f} MB")
if self.gpu_configured:
gpus = tf.config.experimental.list_physical_devices('GPU')
for i, gpu in enumerate(gpus):
print(f"GPU {i}: {gpu.name}")
print(f"TensorFlow Version: {tf.__version__}")
print(f"PyTorch Version: {torch.__version__}")
print(f"NumPy Version: {np.__version__}")
print(f"Pandas Version: {pd.__version__}")
print("=" * 60)
# Initialize and configure environment
env_config = EnvironmentSetup()
env_config.configure_environment()
OPTIMAL_WORKERS = env_config.optimal_workers
============================================================ ENVIRONMENT CONFIGURATION SUMMARY ============================================================ Random seeds set to 42 for reproducibility CUDA is not available No GPU found in TensorFlow. Using CPU for computation. Configured CPU threading for optimal performance Configured 12 workers for parallel processing (CPU cores: 20) Visualization settings configured (seaborn whitegrid, matplotlib default) Pandas display options configured (max_columns=None, max_rows=100) Warning filters configured (suppressed for cleaner output) CONFIGURATION DETAILS: Random Seed: 42 CPU Workers: 12 GPU Configured: False CUDA Available: False Force GPU: True TensorFlow Version: 2.20.0-rc0 PyTorch Version: 2.7.1+cpu NumPy Version: 2.2.6 Pandas Version: 2.3.1 ============================================================
The EnvironmentSetup class centralizes system configuration for optimal deep learning performance, automatically detecting and configuring GPU/CPU resources, setting reproducibility seeds, and optimizing memory management. This ensures consistent results across different hardware environments while maximizing computational efficiency for our neural network training.# Initialize and configure environment
try:
from google.colab import drive
COLAB_DRIVE_PATH = '/content/drive'
drive.mount(COLAB_DRIVE_PATH)
DATA_DIRECTORY = f"{COLAB_DRIVE_PATH}/MyDrive/data"
MUSIC_DATA_DIRECTORY = f"{DATA_DIRECTORY}/midiclassics"
IS_COLAB = True
print(f"Google Drive mounted at {COLAB_DRIVE_PATH}")
except:
DATA_DIRECTORY = "data"
MUSIC_DATA_DIRECTORY = f"{DATA_DIRECTORY}\\midiclassics"
IS_COLAB = False
print("Running in local environment, not Google Colab")
MUSICAL_FEATURES_DF_PATH = f'{DATA_DIRECTORY}/features/musical_features_df.pkl'
HARMONIC_FEATURES_DF_PATH = f'{DATA_DIRECTORY}/features/harmonic_features_df.pkl'
NOTE_SEQUENCES_PATH = f'{DATA_DIRECTORY}/features/note_sequences.npy'
NOTE_SEQUENCES_LABELS_PATH = f'{DATA_DIRECTORY}/features/sequence_labels.npy'
NOTE_MAPPING_PATH = f'{DATA_DIRECTORY}/features/note_mapping.pkl'
MODEL_ARTIFACTS_PATH = f'{DATA_DIRECTORY}/model/composer_classification_model_artifacts.pkl'
MODEL_HISTORY_PATH = f'{DATA_DIRECTORY}/model/composer_classification_model_history.pkl'
MODEL_PATH = f'{DATA_DIRECTORY}/model/composer_classification_model.keras'
MODEL_BEST_PATH = f'{DATA_DIRECTORY}/model/composer_classification_model_best.keras'
# List of target composers for classification
TARGET_COMPOSERS = ['Bach', 'Beethoven', 'Chopin', 'Mozart']
print(f"Target composers for classification: {TARGET_COMPOSERS}")
Running in local environment, not Google Colab Target composers for classification: ['Bach', 'Beethoven', 'Chopin', 'Mozart']
This project aims to develop an accurate deep learning–based system for composer classification, using MIDI data as the primary input. To achieve this, we implement a MidiProcessor class (below) that streamlines the end-to-end preprocessing pipeline. It includes the following:
Scanning the MIDI dataset
load_midi_files()searches through composer-specific folders, recursively finding.midand.midifiles.- Uses parallel processing via
ThreadPoolExecutorto scan multiple composers at once. - Returns a
pandasDataFrame containing file paths, composer labels, and filenames for downstream processing.
Extracting notes from MIDI files
extract_notes_from_midi()parses a single MIDI file, extracting individual notes and chords (converted into pitch strings).- Limits extraction to a maximum number of notes for efficiency.
- Includes fallback handling for flat MIDI structures and skips empty or corrupted files.
extract_notes_from_midi_parallel()enables batch note extraction in parallel with a progress bar for large datasets.
Extracting detailed musical features
extract_musical_features()analyzes each MIDI file to gather rich metadata:- Total notes, total duration, time signature, key and confidence, tempo.
- Pitch statistics (average, range, standard deviation), intervals, note durations.
- Structural features like number of parts, measures, chords, rests, rest ratios, and average notes per measure.
- Instrument detection and chord type analysis.
extract_musical_features_parallel()runs this process in parallel for scalability.
Creating note sequences for deep learning models
create_note_sequences()builds a vocabulary of unique notes from the dataset.- Converts notes into integer representations and slices them into fixed-length sequences (e.g., 100-note windows) for LSTM/CNN model training.
- Includes batching and memory safeguards to handle large datasets efficiently.
Preprocessing and filtering the dataset
preprocess_midi_files()filters out invalid, duplicate, corrupted, too-short, or low-key-confidence MIDI files.- Uses file hashing to detect duplicates and minimum thresholds for duration and key confidence.
- Tracks processing statistics to provide a clear summary of dataset quality after filtering.
class MidiProcessor:
def __init__(self):
self._file_cache = {} # Cache for parsed files
self._feature_cache = {} # Cache for extracted features
def load_midi_files(self, data_dir, max_files_per_composer=None, n_jobs=None):
if n_jobs is None:
n_jobs = OPTIMAL_WORKERS
start_time = time.time()
# Get all composer directories
composers = [c for c in os.listdir(data_dir)
if os.path.isdir(os.path.join(data_dir, c))]
def scan_composer(composer):
composer_path = os.path.join(data_dir, composer)
try:
# Get all MIDI files with recursive search
midi_files = []
for root, dirs, files in os.walk(composer_path):
for file in files:
if file.lower().endswith(('.mid', '.midi')):
# Get path relative to composer_path
rel_path = os.path.relpath(os.path.join(root, file), composer_path)
midi_files.append(rel_path)
# Apply limit if specified
if max_files_per_composer:
midi_files = midi_files[:max_files_per_composer]
# Create file info list
return [
{
'file_path': os.path.join(composer_path, midi_file),
'composer': composer,
'filename': midi_file
}
for midi_file in midi_files
]
except Exception as e:
print(f"Error scanning {composer}: {e}")
return []
# Parallel composer scanning
all_files = []
with ThreadPoolExecutor(max_workers=n_jobs) as executor:
futures = [executor.submit(scan_composer, composer) for composer in composers]
for future in as_completed(futures):
composer_files = future.result()
all_files.extend(composer_files)
elapsed = time.time() - start_time
print(f"Loaded {len(all_files)} MIDI files from {len(composers)} composers in {elapsed:.2f}s")
return pd.DataFrame(all_files)
@staticmethod
def extract_notes_from_midi(midi_path, max_notes=500):
try:
# Parse once and extract efficiently
midi = converter.parse(midi_path)
notes = []
# Note extraction with limits
if hasattr(midi, 'parts') and midi.parts:
# Process only first few parts for speed
for part in midi.parts[:2]: # Limit to 2 parts
part_notes = part.recurse().notes
for element in part_notes:
if len(notes) >= max_notes:
break
if isinstance(element, note.Note):
notes.append(str(element.pitch))
elif isinstance(element, chord.Chord):
notes.append('.'.join(str(n) for n in element.normalOrder))
if len(notes) >= max_notes:
break
else:
# Flat structure
for element in midi.flat.notes:
if len(notes) >= max_notes:
break
if isinstance(element, note.Note):
notes.append(str(element.pitch))
elif isinstance(element, chord.Chord):
notes.append('.'.join(str(n) for n in element.normalOrder))
return notes[:max_notes] # Ensure we don't exceed limit
except Exception as e:
print(f"Error processing {midi_path}: {str(e)}")
return []
@staticmethod
def extract_notes_batch(midi_paths_batch, max_notes=500):
results = []
for midi_path in midi_paths_batch:
notes = MidiProcessor.extract_notes_from_midi(midi_path, max_notes)
results.append(notes)
return results
@staticmethod
def extract_notes_from_midi_parallel(midi_paths, max_notes=500, n_jobs=None):
if n_jobs is None:
n_jobs = OPTIMAL_WORKERS
total_files = len(midi_paths)
# Create batches for better memory management
batch_size = max(1, len(midi_paths) // (n_jobs * 2))
batches = [midi_paths[i:i + batch_size] for i in range(0, len(midi_paths), batch_size)]
results = [None] * len(midi_paths)
# Create a progress bar
pbar = tqdm(total=total_files, desc="Extracting notes from MIDI files")
def process_batch(batch_data):
batch_idx, batch_paths = batch_data
batch_results = MidiProcessor.extract_notes_batch(batch_paths, max_notes)
# Update progress bar for each file in the batch
pbar.update(len(batch_paths))
return batch_idx, batch_results
try:
# Process batches in parallel
with ThreadPoolExecutor(max_workers=n_jobs) as executor:
batch_data = [(i, batch) for i, batch in enumerate(batches)]
futures = [executor.submit(process_batch, data) for data in batch_data]
for future in as_completed(futures):
batch_idx, batch_results = future.result()
batch_start = batch_idx * batch_size
for i, notes in enumerate(batch_results):
if batch_start + i < len(results):
results[batch_start + i] = notes
finally:
# Make sure to close the progress bar
pbar.close()
# Report completion stats
successful = sum(1 for r in results if r is not None and len(r) > 0)
print(f"\nNote extraction complete: {successful}/{total_files} files processed successfully")
return results
@staticmethod
def extract_musical_features(midi_path):
try:
midi = converter.parse(midi_path)
features = {}
# Basic counts
all_notes = list(midi.flat.notes)
features['total_notes'] = len(all_notes)
features['total_duration'] = float(midi.duration.quarterLength) if midi.duration else 0
# Time signature (quick lookup)
time_sigs = midi.getTimeSignatures()
if time_sigs:
features['time_signature'] = f"{time_sigs[0].numerator}/{time_sigs[0].denominator}"
else:
features['time_signature'] = "4/4"
# Key analysis
try:
key_sigs = midi.analyze('key')
features['key'] = str(key_sigs) if key_sigs else "C major"
if hasattr(key_sigs, 'correlationCoefficient'):
features['key_confidence'] = float(abs(key_sigs.correlationCoefficient))
else:
features['key_confidence'] = 0.5
except:
features['key'] = "C major"
features['key_confidence'] = 0.5
# Tempo
tempo_markings = midi.flat.getElementsByClass('MetronomeMark')
features['tempo'] = float(tempo_markings[0].number) if tempo_markings else 120.0
# Pitch features (vectorized calculation)
pitches = []
durations = []
for n in all_notes[:1000]: # Limit for speed
if isinstance(n, note.Note):
pitches.append(n.pitch.midi)
durations.append(float(n.duration.quarterLength))
elif isinstance(n, chord.Chord):
pitches.append(n.root().midi)
durations.append(float(n.duration.quarterLength))
if pitches:
pitches_array = np.array(pitches)
features['avg_pitch'] = float(np.mean(pitches_array))
features['pitch_range'] = float(np.ptp(pitches_array))
features['pitch_std'] = float(np.std(pitches_array))
# Intervals (vectorized)
if len(pitches) > 1:
intervals = np.abs(np.diff(pitches_array))
features['avg_interval'] = float(np.mean(intervals))
features['interval_std'] = float(np.std(intervals))
else:
features['avg_interval'] = 0.0
features['interval_std'] = 0.0
else:
features.update({
'avg_pitch': 60.0, 'pitch_range': 0.0, 'pitch_std': 0.0,
'avg_interval': 0.0, 'interval_std': 0.0
})
# Duration features (vectorized)
if durations:
dur_array = np.array(durations)
features['avg_duration'] = float(np.mean(dur_array))
features['duration_std'] = float(np.std(dur_array))
else:
features['avg_duration'] = 1.0
features['duration_std'] = 0.0
# Structural features (limited for speed)
features['num_parts'] = len(midi.parts) if hasattr(midi, 'parts') else 1
# Count specific elements (limited)
limited_elements = list(midi.flat.notesAndRests)[:500] # Limit for speed
chords = [el for el in limited_elements if isinstance(el, chord.Chord)]
rests = [el for el in limited_elements if isinstance(el, note.Rest)]
features['num_chords'] = len(chords)
features['num_rests'] = len(rests)
features['rest_ratio'] = len(rests) / features['total_notes'] if features['total_notes'] > 0 else 0
# Measures (efficient approximation)
if hasattr(midi, 'parts') and midi.parts:
measures = list(midi.parts[0].getElementsByClass('Measure'))
features['num_measures'] = len(measures) if measures else max(1, int(features['total_duration'] / 4))
else:
features['num_measures'] = max(1, int(features['total_duration'] / 4))
features['avg_notes_per_measure'] = features['total_notes'] / features['num_measures'] if features['num_measures'] > 0 else 0
# Instruments (simplified)
instruments = []
if hasattr(midi, 'parts') and midi.parts:
for part in midi.parts[:3]: # Limit to first 3 parts
try:
instr = part.getInstrument(returnDefault=True)
instruments.append(str(instr))
except:
instruments.append('Piano')
else:
instruments = ['Piano']
features['instruments'] = list(set(instruments))
# Chord types (limited analysis)
chord_types = []
for c in chords[:10]: # Limit to first 10 chords
try:
chord_types.append(c.commonName)
except:
chord_types.append('Unknown')
features['chord_types'] = list(set(chord_types))
return features
except Exception as e:
print(f"Error extracting features from {midi_path}: {str(e)}")
return {
'total_notes': 0, 'total_duration': 0, 'time_signature': '4/4',
'key': 'C major', 'key_confidence': 0, 'tempo': 120.0,
'avg_pitch': 60.0, 'pitch_range': 0, 'pitch_std': 0,
'avg_duration': 1.0, 'duration_std': 0,
'avg_interval': 0, 'interval_std': 0, 'num_parts': 1,
'num_chords': 0, 'num_rests': 0, 'rest_ratio': 0,
'num_measures': 1, 'avg_notes_per_measure': 0,
'instruments': ['Piano'], 'chord_types': []
}
@staticmethod
def extract_musical_features_parallel(midi_paths, n_jobs=None):
if n_jobs is None:
n_jobs = OPTIMAL_WORKERS
total_files = len(midi_paths)
results = [None] * total_files
# Create a progress bar
pbar = tqdm(total=total_files, desc="Extracting musical features")
def worker(idx, midi_path):
try:
features = MidiProcessor.extract_musical_features(midi_path)
return idx, features
except Exception as e:
print(f"\nError processing {midi_path}: {e}")
return idx, MidiProcessor.extract_musical_features(None) # Return empty features
finally:
# Update progress bar
pbar.update(1)
try:
with ThreadPoolExecutor(max_workers=n_jobs) as executor:
# Submit all tasks
futures = [executor.submit(worker, idx, path) for idx, path in enumerate(midi_paths)]
# Process results as they complete
for future in as_completed(futures):
try:
idx, features = future.result()
results[idx] = features
except Exception as e:
print(f"\nError in feature extraction worker: {e}")
finally:
# Make sure to close the progress bar
pbar.close()
# Report completion stats
successful = sum(1 for r in results if r is not None and r.get('total_notes', 0) > 0)
print(f"\nFeature extraction complete: {successful}/{total_files} files processed successfully")
return results
@staticmethod
def create_note_sequences(notes_list, sequence_length=100):
print("Building vocabulary...")
# Vocabulary building
all_notes = []
for notes in notes_list:
if notes: # Skip empty note lists
all_notes.extend(notes[:1000]) # Limit notes per file for speed
unique_notes = sorted(set(all_notes))
note_to_int = {note: i for i, note in enumerate(unique_notes)}
print(f"Vocabulary size: {len(unique_notes)}")
print("Creating sequences...")
# Create sequences with memory optimization
sequences = []
batch_size = 1000
for i in range(0, len(notes_list), batch_size):
batch_notes = notes_list[i:i + batch_size]
batch_sequences = []
for notes in batch_notes:
if len(notes) >= sequence_length:
# Convert notes to integers (with error handling)
note_ints = []
for note in notes:
if note in note_to_int:
note_ints.append(note_to_int[note])
# Create sequences from this file
for j in range(len(note_ints) - sequence_length + 1):
seq = note_ints[j:j + sequence_length]
if len(seq) == sequence_length: # Ensure correct length
batch_sequences.append(seq)
sequences.extend(batch_sequences)
# Progress update
if i % (batch_size * 10) == 0:
print(f"Processed {min(i + batch_size, len(notes_list))}/{len(notes_list)} files, "
f"created {len(sequences)} sequences")
# Memory cleanup
if len(sequences) > 50000: # Prevent memory overflow
break
print(f"Total sequences created: {len(sequences)}")
return np.array(sequences), note_to_int, unique_notes
@staticmethod
def preprocess_midi_files(file_df, min_duration=5.0, min_key_confidence=0.7, verbose=True, n_jobs=None):
if n_jobs is None:
n_jobs = OPTIMAL_WORKERS
processed_files = []
seen_hashes = set()
total = len(file_df)
stats = {
'total': total,
'corrupted': 0,
'zero_length': 0,
'duplicates': 0,
'too_short': 0,
'ambiguous_key': 0,
'kept': 0
}
def process_file(row_data):
idx, row = row_data
path = row['file_path']
try:
# Quick file validation
if not os.path.exists(path) or os.path.getsize(path) == 0:
return ('zero_length', None)
# File hash for deduplication
with open(path, 'rb') as f:
file_hash = hashlib.md5(f.read()).hexdigest()
# Basic MIDI parsing
score = converter.parse(path)
duration = score.duration.seconds if score.duration else 0
if duration < min_duration:
return ('too_short', None)
# Key confidence check (if needed)
if min_key_confidence > 0:
try:
key_obj = score.analyze('key')
if hasattr(key_obj, 'correlationCoefficient'):
confidence = abs(key_obj.correlationCoefficient)
else:
confidence = 1.0
if confidence < min_key_confidence:
return ('ambiguous_key', None)
except:
return ('ambiguous_key', None)
return ('kept', (file_hash, row))
except Exception as e:
return ('corrupted', None)
completed = 0
with ThreadPoolExecutor(max_workers=n_jobs) as executor:
row_data = [(idx, row) for idx, row in file_df.iterrows()]
futures = [executor.submit(process_file, data) for data in row_data]
for future in as_completed(futures):
result, data = future.result()
completed += 1
if verbose and completed % 50 == 0:
percent = (completed / total) * 100
print(f"\rProcessing: {completed}/{total} ({percent:.1f}%)", end='', flush=True)
if result == 'kept' and data:
file_hash, row = data
if file_hash not in seen_hashes:
seen_hashes.add(file_hash)
processed_files.append(row)
stats['kept'] += 1
else:
stats['duplicates'] += 1
else:
stats[result] += 1
if verbose:
print() # New line after progress
print("\nPreprocessing Results:")
for key, value in stats.items():
print(f"{key.replace('_', ' ').title()}: {value}")
return pd.DataFrame(processed_files)
The MidiProcessor above addresses the challenges of preparing a large, multi-class MIDI dataset.
Manual data cleaning for such datasets can be slow and prone to error, especially when handling files from different sources with varying lengths, complexities, and numerous features. By automating our MIDI dataset scanning, parallelized note and feature extraction, sequence creation, and filtering, this pipeline provides us with quality input data that captures some key musical attributes necessary for training LSTM and CNN models.
The next preprocessing step initializes the MidiProcessor and prepares the dataset for deep learning–based composer classification. The pipeline:
Initialization & Metadata Loading
- Creates a
MidiProcessorinstance and loads all MIDI file metadata into a Pandas DataFrame from the specified dataset directory.
- Creates a
Filtering Target Composers
- Restricts the dataset to a predefined set of composers (
TARGET_COMPOSERS) and removes any files with missing or invalid paths.
- Restricts the dataset to a predefined set of composers (
Dataset Overview
- Counts and prints the total number of MIDI files before and after filtering to track dataset size and integrity.
Data Visualization
- Generates two plots for quick dataset inspection:
- Bar Chart: Displays the number of valid MIDI files for each target composer, with counts labeled on the bars.
- Pie Chart: Shows the proportion of MIDI files per composer, giving a visual breakdown of class distribution.
- Generates two plots for quick dataset inspection:
Justification:
These steps ensure that the dataset used for training is both relevant (only target composers) and valid (no broken paths or duplicates). The visualizations provide an immediate overview of data balance, which is crucial for understanding potential class imbalance issues before model training.
# Initialize MidiProcessor
midi_processor = MidiProcessor()
# Load MIDI file metadata into a DataFrame
all_midi_df = midi_processor.load_midi_files(MUSIC_DATA_DIRECTORY)
# Define colors dictionary for visualization
colors = dict(zip(TARGET_COMPOSERS, sns.color_palette(env_config.color_pallete, len(TARGET_COMPOSERS))))
print(f"Total MIDI files found: {len(all_midi_df)}")
# Filter for required composers only
midi_df = all_midi_df[all_midi_df['composer'].isin(TARGET_COMPOSERS)].reset_index(drop=True)
print(f"Filtered MIDI files for target composers ({len(TARGET_COMPOSERS)}): {len(midi_df)}")
# Remove files with missing or invalid paths
midi_df = midi_df[midi_df['file_path'].apply(os.path.exists)].reset_index(drop=True)
# Preprocess MIDI files (clean, deduplicate, filter)
# midi_df = midi_processor.preprocess_midi_files(midi_df)
print(f"Valid MIDI files after preprocessing: {len(midi_df)}")
# Count files for required composers
required_composer_counts = midi_df['composer'].value_counts()
# Close any existing plots to start fresh
plt.close('all')
fig, axs = plt.subplots(1, 2, figsize=(12, 4))
# Plot 1: Bar chart of target composers
sns.barplot(
x=required_composer_counts.index,
y=required_composer_counts.values,
palette=env_config.color_pallete,
ax=axs[0]
)
axs[0].set_title('MIDI Files per Composer', fontsize=14)
axs[0].set_xlabel('Composer', fontsize=12)
axs[0].set_ylabel('Number of Files', fontsize=12)
# Add count numbers on top of the bars
for i, count in enumerate(required_composer_counts.values):
percentage = 100 * count / required_composer_counts.sum()
axs[0].text(i, count + 5, f"{count}", ha='center')
# Plot 2: Pie chart showing proportion of composers
axs[1].pie(
required_composer_counts.values,
labels=required_composer_counts.index,
autopct='%1.1f%%',
startangle=90,
colors=[colors[composer] for composer in required_composer_counts.index],
shadow=True
)
axs[1].set_title('Proportion of MIDI Files by Composer', fontsize=14)
axs[1].axis('equal')
plt.tight_layout()
plt.show()
Loaded 1643 MIDI files from 4 composers in 0.02s Total MIDI files found: 1643 Filtered MIDI files for target composers (4): 1643 Valid MIDI files after preprocessing: 1643

# To handle the data imbalance, we can sample a fixed number of files per composer
if SAMPLING == True:
midi_df = midi_df.groupby('composer').head(SAMPLING_FILES_PER_COMPOSER).reset_index(drop=True)
print(f"Reduced MIDI files to {SAMPLING_FILES_PER_COMPOSER} per composer: Total Files: {len(midi_df)}")
else:
print("Sampling is disabled, using all available MIDI files.")
Sampling is disabled, using all available MIDI files.
Dataset Summary and Class Distribution Analysis
The dataset contains 1,640 MIDI files across 4 target composers (Bach, Mozart, Beethoven, and Chopin). All files were successfully loaded, filtered for the selected composers, and passed preprocessing without removals, indicating good overall data integrity.
Key Findings from our Visualizations:
Bar Chart – MIDI Files per Composer
- Bach has the largest number of files (1,024), followed by Mozart (257), Beethoven (220), and Chopin (136).
- This shows a significant difference in data availability among composers.
Pie Chart – Proportion of MIDI Files by Composer
- Bach's works make up 62.6% of the dataset.
- Mozart accounts for 15.7%, Beethoven 13.4%, and Chopin only 8.3%.
Data Imbalance Considerations:
The dataset is heavily imbalanced, with Bach dominating the sample size. Such imbalance can bias the deep learning model toward predicting Bach more often, potentially reducing classification accuracy for underrepresented composers like Chopin. This imbalance will need to be addressed during preprocessing or model training possible strategies include data augmentation, class weighting, or sampling techniques to create a more balanced input distribution.
5.1 HarmonyAnalyzer:¶
HarmonyAnalyzer – Purpose and Role in Feature Extraction
The HarmonyAnalyzer is a specialized preprocessing tool we designed to extract high-level harmonic and tonal features from MIDI data before feeding it into the LSTM and CNN composer classification model. These features go beyond note or pitch features by working to quantify how composers use harmony, tonality, and modulation in their works—key stylistic markers for distinguishing between composers. We felt this provided an edge to our model using special domain knowledge.
Note: We also provide in-line code commenting to help detail each harmonic feature and it's musical importance.
Why These Analyses Are Needed¶
Traditional statistical features (e.g., average pitch, tempo, note durations) are important, however some deeper stylistic patterns that define a composer’s “musical fingerprint” seemed pertinent to include.
Classical composers differ greatly in harmonic language, use of consonance/dissonance, modulations, and cadences. Capturing these traits creates a deeper musical theory based feature set, with an aim to improving model performance for composer prediction down the pipeline.
Main Components in Harmony Analyzer Class¶
Chord and Progression Analysis (
analyze_chords_and_progressions)- Extracts total and unique chord counts.
- Calculates chord quality ratios (major, minor, diminished, augmented).
- Detects occurrences of common classical progressions using 'old school' roman numeral analysis(e.g., I–V–vi–IV).
- Measures chord inversion usage and root position frequency.
- Why: Different composers favor specific chord types and progressions, which can be strong stylistic indicators.
Dissonance Analysis (
analyze_dissonance)- Quantifies average, maximum, and variance of dissonance in sliding note windows.
- Measures tritone frequency (a historically important dissonance).
- Why: Composers vary in their tolerance for tension—Baroque composers may use consonance more often, while Romantic composers may use richer dissonances.
Tonality Analysis (
analyze_tonality)- Calculates how often the tonic note/chord appears in melody and bass.
- Tracks cadential tonic usage in phrase endings.
- Why: Staying “close to home” harmonically vs. frequent departures is a defining compositional choice.
Key Modulation Analysis (
analyze_key_modulations)- Detects key changes across the score using multiple key-finding methods.
- Calculates modulation rate, key diversity, stability, and distances between keys on the circle of fifths.
- Why: Some composers (e.g., Beethoven) modulate frequently to explore harmonic space, while others remain harmonically stable.
Cadence Analysis (
analyze_cadences)- Detects authentic (V–I), plagal (IV–I), and deceptive (V–vi) cadences.
- Calculates cadence type ratios and total cadences.
- Why: Cadence preferences can strongly signal the harmonic era and composer identity.
Value for Model Preparation¶
By combining these advanced harmonic features with the statistical ones, the dataset gains musically meaningful, high-level descriptors that directly reflect compositional style. This gives the deep learning model access to nuanced harmonic behavior, improving classification accuracy and interpretability.
class HarmonyAnalyzer:
"""Analyzer for harmony-related features."""
def __init__(self, np_module):
self.np = np_module
self.has_gpu = np_module.__name__ == 'cupy'
# Perfect/major/minor consonances
self.consonant_intervals = {0, 3, 4, 5, 7, 8, 9, 12}
# The More dissonant intervals
self.dissonant_intervals = {1, 2, 6, 10, 11}
# Common classical chord progressions
self.common_progressions = {
'I-V-vi-IV': [(1, 5, 6, 4)],
'vi-IV-I-V': [(6, 4, 1, 5)],
'I-vi-IV-V': [(1, 6, 4, 5)],
'ii-V-I': [(2, 5, 1)],
'I-IV-V-I': [(1, 4, 5, 1)],
'vi-ii-V-I': [(6, 2, 5, 1)]
}
# Circle of fifths for key relationships
self.circle_of_fifths = {
'C': 0, 'G': 1, 'D': 2, 'A': 3, 'E': 4, 'B': 5, 'F#': 6, 'Gb': 6,
'Db': 5, 'Ab': 4, 'Eb': 3, 'Bb': 2, 'F': 1
}
# Relative major/minor relationships
self.relative_keys = {
('C', 'major'): ('A', 'minor'),
('G', 'major'): ('E', 'minor'),
('D', 'major'): ('B', 'minor'),
('A', 'major'): ('F#', 'minor'),
('E', 'major'): ('C#', 'minor'),
('B', 'major'): ('G#', 'minor'),
('F#', 'major'): ('D#', 'minor'),
('Db', 'major'): ('Bb', 'minor'),
('Ab', 'major'): ('F', 'minor'),
('Eb', 'major'): ('C', 'minor'),
('Bb', 'major'): ('G', 'minor'),
('F', 'major'): ('D', 'minor'),
}
# Add reverse mappings
for maj, min in list(self.relative_keys.items()):
self.relative_keys[min] = maj
def analyze_chords_and_progressions(self, score, window_size, overlap, shared_data):
"""Analyze chord progressions patterns.
We should embrace the "old school" musical analysis process here.
Roman rumerals are traditionally used in musical analysis as a means
to evaluate how composers go from one idea to the next, or one
feeling to the next via their chosen chord progressions. How often
composers use different chord qualities, such as major/minor/
or augmented/diminished defines their stylistic tendencies and
compositional choices over time. Chord inversions are related
indicators, as they inform how each note in a harmonic chord is
stacked, representing key variations of musical harmononic analysis.
"""
features = {}
try:
# Use shared data
chords = shared_data.get('chords', [])
key_signature = shared_data.get('key_signature')
if not chords or not key_signature:
return self.empty_harmony_features()
features['total_chords'] = len(chords)
# Use batch processing for better performance
batch_size = min(100, max(1, len(chords) // 2))
# Pre-compute pitchedCommonName for optimization
pitchedCommonNames = [c.pitchedCommonName for c in chords
if hasattr(c, 'pitchedCommonName')]
features['unique_chords'] = len(set(pitchedCommonNames))
# Process chords in batches using thread pool
chord_qualities, roman_numerals, inversions = self._process_chord_batches(
chords, key_signature, batch_size)
# Calculate chord type ratios
quality_counts = Counter(chord_qualities)
chord_count = len(chords) if chords else 1 # Avoid division by zero
features['major_chord_ratio'] = quality_counts.get('major', 0) / chord_count
features['minor_chord_ratio'] = quality_counts.get('minor', 0) / chord_count
features['diminished_chord_ratio'] = quality_counts.get('diminished', 0) / chord_count
features['augmented_chord_ratio'] = quality_counts.get('augmented', 0) / chord_count
# Chord progression analysis
if len(roman_numerals) >= 4:
progression_counts = self._find_chord_progressions(roman_numerals)
features.update(progression_counts)
else:
for prog_name in self.common_progressions:
features[f'progression_{prog_name.lower().replace("-", "_")}_count'] = 0
# Chord inversion analysis
if inversions:
inv_array = self.np.array(inversions, dtype=float)
features['avg_chord_inversion'] = float(self.np.mean(inv_array))
features['root_position_ratio'] = inversions.count(0) / len(inversions)
else:
features['avg_chord_inversion'] = 0
features['root_position_ratio'] = 0
except Exception:
features = self.empty_harmony_features()
return features
def _process_chord_batches(self, chords, key_signature, batch_size):
"""Process chords in batches for better performance."""
def process_chord_batch(chord_batch):
qualities = []
rns = []
invs = []
for c in chord_batch:
try:
qualities.append(c.quality)
rns.append(roman.romanNumeralFromChord(c, key_signature).figure)
invs.append(c.inversion())
except:
qualities.append('unknown')
rns.append('Unknown')
invs.append(0)
return qualities, rns, invs
# Split chords into batches
chord_batches = [chords[i:i+batch_size] for i in range(0, len(chords), batch_size)]
# Process batches in parallel
chord_qualities = []
roman_numerals = []
inversions = []
with ThreadPoolExecutor() as executor:
batch_results = list(executor.map(process_chord_batch, chord_batches))
# Combine results
for qualities, rns, invs in batch_results:
chord_qualities.extend(qualities)
roman_numerals.extend(rns)
inversions.extend(invs)
return chord_qualities, roman_numerals, inversions
def _find_chord_progressions(self, roman_numerals):
"""Find common chord progression patterns."""
progression_counts = {}
# Use a lookup table for faster scale degree extraction
scale_degree_map = {
'I': 1, 'II': 2, 'III': 3, 'IV': 4, 'V': 5, 'VI': 6, 'VII': 7,
'i': 1, 'ii': 2, 'iii': 3, 'iv': 4, 'v': 5, 'vi': 6, 'vii': 7
}
# Pre-process roman numerals to scale degrees efficiently
scale_degrees = []
for rn in roman_numerals:
# Extract first 1-2 characters for faster lookup
rn_start = rn[:2] if len(rn) > 1 else rn[:1]
rn_start = rn_start.upper() # Normalize case
# Fast lookup
if rn_start in scale_degree_map:
scale_degrees.append(scale_degree_map[rn_start])
elif rn_start[0] in scale_degree_map:
scale_degrees.append(scale_degree_map[rn_start[0]])
else:
scale_degrees.append(0) # Unknown
# Convert to numpy array for faster pattern matching
scale_degrees_array = self.np.array(scale_degrees)
# Process each progression pattern efficiently
for prog_name, patterns in self.common_progressions.items():
count = 0
for pattern in patterns:
pattern_length = len(pattern)
if len(scale_degrees) >= pattern_length:
# Use vectorized operations for pattern matching when possible
if self.has_gpu and len(scale_degrees) > 1000:
# GPU-optimized pattern matching
pattern_array = self.np.array(pattern)
matches = 0
# Sliding window implementation optimized for GPU
for i in range(len(scale_degrees) - pattern_length + 1):
window = scale_degrees_array[i:i+pattern_length]
if self.np.array_equal(window, pattern_array):
matches += 1
count += matches
else:
# CPU version with optimized lookups
pattern_tuple = tuple(pattern)
# Use sliding window approach
for i in range(len(scale_degrees) - pattern_length + 1):
if tuple(scale_degrees[i:i+pattern_length]) == pattern_tuple:
count += 1
progression_counts[f'progression_{prog_name.lower().replace("-", "_")}_count'] = count
return progression_counts
def analyze_dissonance(self, score, window_size, overlap, shared_data):
"""Analyze dissonance measurements.
Dissonance in music theory is a measurement of perceptual clashing
or tension between either 2 or more notes, whether they are in
a harmonic setting (i.e. in a triad), or melodically over time.
It's a perceptual concept, as one person might find something more
dissonant than another (experiemental jazz vs. orderly Mozart), yet
even though it's perceptual we have some preconceived notions of
note relationships coresponding to tonal expectations. More dissonance
equates to less harmonicity, and vice versa-- a great measurement
for our classification purposes.
"""
features = {}
try:
# Use shared data
notes = shared_data.get('notes', [])
# Early return for empty notes
if not notes:
return self.empty_dissonance_features()
# Extract all pitches
all_pitches = []
for note in notes:
if hasattr(note, 'pitch'):
all_pitches.append(note.pitch.midi)
if not all_pitches:
return self.empty_dissonance_features()
# Convert to numpy array for faster processing
all_pitches_array = self.np.array(all_pitches)
# Create sliding windows of notes
window_size_notes = 10 # Fixed size for consistent analysis
dissonance_samples = self._analyze_dissonance_windows(all_pitches_array, window_size_notes)
# Calculate statistics
if dissonance_samples:
dissonance_array = self.np.array(dissonance_samples)
features['avg_dissonance'] = float(self.np.mean(dissonance_array))
features['max_dissonance'] = float(self.np.max(dissonance_array))
features['dissonance_variance'] = float(self.np.var(dissonance_array))
else:
features['avg_dissonance'] = 0
features['max_dissonance'] = 0
features['dissonance_variance'] = 0
# Tritone analysis
if len(all_pitches_array) > 1:
# Compute consecutive intervals
intervals = self.np.abs(self.np.diff(all_pitches_array)) % 12
tritone_count = self.np.sum(intervals == 6)
features['tritone_frequency'] = float(tritone_count) / len(notes)
else:
features['tritone_frequency'] = 0
except Exception:
features = self.empty_dissonance_features()
return features
def _analyze_dissonance_windows(self, all_pitches_array, window_size_notes):
# Optimize for large datasets with adaptive chunking
num_chunks = min(os.cpu_count() or 4, 8)
chunk_size = max(10, len(all_pitches_array) // num_chunks)
# Process sliding windows more efficiently
def analyze_windows_batch(start_idx, end_idx):
batch_results = []
for i in range(start_idx, min(end_idx, len(all_pitches_array) - window_size_notes + 1), 3):
window = all_pitches_array[i:i+window_size_notes]
if len(window) < 2:
continue
# Create all pairwise combinations efficiently
if self.has_gpu:
# GPU-optimized version
pitches_col = window.reshape(-1, 1)
pitches_row = window.reshape(1, -1)
interval_matrix = self.np.abs(pitches_col - pitches_row) % 12
# Get upper triangle of matrix excluding diagonal
intervals = interval_matrix[self.np.triu_indices_from(interval_matrix, k=1)]
# Count dissonant intervals
dissonant_count = 0
for interval in intervals:
if int(interval) in self.dissonant_intervals:
dissonant_count += 1
if len(intervals) > 0:
batch_results.append(dissonant_count / len(intervals))
else:
# CPU version
window_dissonance = 0
note_pairs = 0
for j in range(len(window)):
for k in range(j+1, len(window)):
interval_semitones = abs(window[j] - window[k]) % 12
if interval_semitones in self.dissonant_intervals:
window_dissonance += 1
note_pairs += 1
if note_pairs > 0:
batch_results.append(window_dissonance / note_pairs)
return batch_results
# Divide work into chunks
chunk_starts = list(range(0, len(all_pitches_array), chunk_size))
chunk_ends = [min(start + chunk_size, len(all_pitches_array)) for start in chunk_starts]
# Process chunks in parallel
all_results = []
with ThreadPoolExecutor() as executor:
all_results = list(executor.map(analyze_windows_batch, chunk_starts, chunk_ends))
# Flatten results
dissonance_samples = []
for result in all_results:
dissonance_samples.extend(result)
return dissonance_samples
def analyze_tonality(self, score, window_size, overlap, shared_data):
"""Analyze how often the tonic is reached.
This is important as it shows how composers stay close to 'home' key
vs. how often they drift into interludes or other musical structures.
A composer like Mozart more often feels safe in the tonic,
whereas Chopin might drift away more often to add a more drifting
sensation to the composition.
"""
features = {}
try:
key_signature = shared_data.get('key_signature')
notes = shared_data.get('notes', [])
chords = shared_data.get('chords', [])
if not key_signature or not notes:
return self.empty_tonality_features()
tonic_pitch = key_signature.tonic
tonic_name = tonic_pitch.name
# Process notes to count tonic occurrences
tonic_hits, bass_tonic_hits = self._count_tonic_notes(notes, tonic_name)
# Process chords to count tonic chords
tonic_chord_count = self._count_tonic_chords(chords, tonic_name)
# Calculate ratios
total_notes = len(notes) if notes else 1 # Avoid division by zero
features['tonic_frequency'] = tonic_hits / total_notes
features['bass_tonic_frequency'] = bass_tonic_hits / total_notes
features['tonic_chord_ratio'] = tonic_chord_count / len(chords) if chords else 0
# Process phrase endings
phrase_endings = self._identify_phrase_endings(score)
cadential_tonic = 0
for ending_chord in phrase_endings:
try:
if ending_chord.root().name == tonic_name:
cadential_tonic += 1
except:
continue
features['cadential_tonic_ratio'] = cadential_tonic / len(phrase_endings) if phrase_endings else 0
except Exception:
features = self.empty_tonality_features()
return features
def _count_tonic_notes(self, notes, tonic_name):
# Process notes in parallel using batches
def process_notes_batch(note_batch):
tonic_count = 0
bass_tonic_count = 0
for note in note_batch:
try:
if hasattr(note, 'pitch') and note.pitch.name == tonic_name:
tonic_count += 1
elif hasattr(note, 'bass') and note.bass().name == tonic_name:
bass_tonic_count += 1
except:
continue
return tonic_count, bass_tonic_count
# Split into batches
batch_size = 100
note_batches = [notes[i:i+batch_size] for i in range(0, len(notes), batch_size)]
# Process batches in parallel
tonic_hits = 0
bass_tonic_hits = 0
with ThreadPoolExecutor() as executor:
# Process notes
note_results = list(executor.map(process_notes_batch, note_batches))
for t_count, bt_count in note_results:
tonic_hits += t_count
bass_tonic_hits += bt_count
return tonic_hits, bass_tonic_hits
def _count_tonic_chords(self, chords, tonic_name):
# Process chords in parallel
def process_chords_batch(chord_batch):
tonic_chord_count = 0
for c in chord_batch:
try:
if c.root().name == tonic_name:
tonic_chord_count += 1
except:
continue
return tonic_chord_count
# Split into batches
batch_size = 100
chord_batches = [chords[i:i+batch_size] for i in range(0, len(chords), batch_size)]
# Process batches in parallel
tonic_chord_count = 0
with ThreadPoolExecutor() as executor:
chord_results = list(executor.map(process_chords_batch, chord_batches))
tonic_chord_count = sum(chord_results)
return tonic_chord_count
def analyze_key_modulations(self, score, window_size, overlap, shared_data):
"""Count key modulations using windowed key analysis.
Modulation is when we move from key center to key center, i.e. from
C Major to Ab Minor (a harmonically unrelated key signature).
Composers in classical music tend to move from key to key when they
want to diverge from a mood or a tonal center into a new avenue of
expressions. This is a feature more common in certain composers,
and a valuable addition to measure from our MIDI files.
"""
features = {}
try:
duration = shared_data.get('total_duration', 0) if shared_data else score.duration.quarterLength
if duration == 0 or duration < window_size:
return self.empty_modulation_features()
# Get note events for analysis
note_events = self._extract_note_events(score)
if len(note_events) < 10: # Need minimum notes for analysis
return self.empty_modulation_features()
# Analyze keys using multiple methods
window_keys = self._analyze_keys_robust(score, note_events, window_size, overlap, duration)
if len(window_keys) < 2:
return self.empty_modulation_features()
# Filter and smooth key sequence
smoothed_keys = self._smooth_key_sequence(window_keys)
# Detect meaningful modulations
modulations = self._detect_meaningful_modulations(smoothed_keys)
# Calculate features
features = self._calculate_modulation_features(modulations, smoothed_keys, duration)
except Exception as e:
print(f"Error in key modulation analysis: {e}")
features = self.empty_modulation_features()
return features
def _extract_note_events(self, score):
"""Extract note events with timing information"""
note_events = []
for element in score.recurse():
if hasattr(element, 'pitch') and hasattr(element, 'offset'):
note_events.append({
'pitch': element.pitch.midi,
'pitch_class': element.pitch.pitchClass,
'offset': float(element.offset),
'duration': float(element.duration.quarterLength)
})
# Sort by onset time
note_events.sort(key=lambda x: x['offset'])
return note_events
def _analyze_keys_robust(self, score, note_events, window_size, overlap, total_duration):
"""
Robust key analysis using multiple methods and validation
"""
step_size = window_size * (1 - overlap)
window_keys = []
current_offset = 0
while current_offset < total_duration - window_size/2:
window_end = current_offset + window_size
# Get notes in current window
window_notes = [
note for note in note_events
if current_offset <= note['offset'] < window_end
]
if len(window_notes) < 3: # Need minimum notes
current_offset += step_size
continue
# Method 1: Krumhansl-Schmuckler key-finding
key1 = self._krumhansl_schmuckler_key(window_notes)
# Method 2: Chord-based key finding
key2 = self._chord_based_key_finding(score, current_offset, window_end)
# Method 3: Simple pitch class distribution
key3 = self._pitch_class_key_finding(window_notes)
# Consensus or best guess
final_key = self._consensus_key([key1, key2, key3])
if final_key:
window_keys.append({
'key': final_key,
'offset': current_offset,
'confidence': self._calculate_key_confidence(window_notes, final_key)
})
current_offset += step_size
return window_keys
def _krumhansl_schmuckler_key(self, window_notes):
"""Krumhansl-Schmuckler key-finding algorithm"""
if not window_notes:
return None
# Krumhansl-Schmuckler profiles
major_profile = [6.35, 2.23, 3.48, 2.33, 4.38, 4.09, 2.52, 5.19, 2.39, 3.66, 2.29, 2.88]
minor_profile = [6.33, 2.68, 3.52, 5.38, 2.60, 3.53, 2.54, 4.75, 3.98, 2.69, 3.34, 3.17]
# Calculate pitch class distribution
pc_distribution = [0] * 12
for note in window_notes:
pc_distribution[note['pitch_class']] += note['duration']
# Normalize
total = sum(pc_distribution)
if total == 0:
return None
pc_distribution = [x/total for x in pc_distribution]
# Find best key
best_correlation = -1
best_key = None
for tonic in range(12):
# Major key correlation
major_corr = self._correlation(
pc_distribution,
major_profile[tonic:] + major_profile[:tonic]
)
# Minor key correlation
minor_corr = self._correlation(
pc_distribution,
minor_profile[tonic:] + minor_profile[:tonic]
)
if major_corr > best_correlation:
best_correlation = major_corr
best_key = (self._pc_to_name(tonic), 'major')
if minor_corr > best_correlation:
best_correlation = minor_corr
best_key = (self._pc_to_name(tonic), 'minor')
return best_key if best_correlation > 0.6 else None
def _chord_based_key_finding(self, score, start_offset, end_offset):
"""Find key based on chord progressions in the window"""
try:
# Extract chords from the window
window_stream = score.measures(
numberStart=int(start_offset/4) + 1,
numberEnd=int(end_offset/4) + 1
)
# Analyze chords
chords = window_stream.chordify()
chord_symbols = []
for chord in chords.recurse().getElementsByClass('Chord'):
if len(chord.pitches) >= 2:
chord_symbols.append(chord.root().pitchClass)
if not chord_symbols:
return None
# Simple chord-to-key mapping
chord_counts = Counter(chord_symbols)
most_common_root = chord_counts.most_common(1)[0][0]
# Heuristic: assume major key based on most common chord root
return (self._pc_to_name(most_common_root), 'major')
except:
return None
def _pitch_class_key_finding(self, window_notes):
"""Simple pitch class distribution key finding"""
if not window_notes:
return None
pc_counts = Counter(note['pitch_class'] for note in window_notes)
if not pc_counts:
return None
# Find most common pitch class
tonic_pc = pc_counts.most_common(1)[0][0]
# Simple heuristic: check if it's more likely major or minor
# Look for characteristic intervals
total_notes = len(window_notes)
third_major = (tonic_pc + 4) % 12
third_minor = (tonic_pc + 3) % 12
major_evidence = pc_counts.get(third_major, 0) / total_notes
minor_evidence = pc_counts.get(third_minor, 0) / total_notes
mode = 'major' if major_evidence >= minor_evidence else 'minor'
return (self._pc_to_name(tonic_pc), mode)
def _consensus_key(self, key_candidates):
"""Get consensus from multiple key-finding methods"""
valid_keys = [k for k in key_candidates if k is not None]
if not valid_keys:
return None
if len(valid_keys) == 1:
return valid_keys[0]
# Count votes
key_votes = Counter(valid_keys)
# If there's a clear winner, use it
most_common = key_votes.most_common(1)[0]
if most_common[1] > 1:
return most_common[0]
# Otherwise, prefer Krumhansl-Schmuckler result (first in list)
return valid_keys[0]
def _smooth_key_sequence(self, window_keys, min_duration=2):
"""Remove brief key changes that are likely analysis errors"""
if len(window_keys) <= 2:
return window_keys
smoothed = []
i = 0
while i < len(window_keys):
current_key = window_keys[i]['key']
# Look ahead to see how long this key lasts
duration = 1
j = i + 1
while j < len(window_keys) and window_keys[j]['key'] == current_key:
duration += 1
j += 1
# If this key change is too brief, skip it
if duration >= min_duration or i == 0 or i == len(window_keys) - 1:
smoothed.extend(window_keys[i:i+duration])
i = j if j > i + 1 else i + 1
return smoothed
def _detect_meaningful_modulations(self, smoothed_keys):
"""Detect meaningful modulations (not just relative major/minor changes)"""
if len(smoothed_keys) < 2:
return []
modulations = []
prev_key = smoothed_keys[0]['key']
for key_info in smoothed_keys[1:]:
current_key = key_info['key']
if current_key != prev_key:
# Check if this is a meaningful modulation
modulation_type = self._classify_modulation(prev_key, current_key)
if modulation_type != 'relative': # Filter out relative major/minor
modulations.append({
'from_key': prev_key,
'to_key': current_key,
'type': modulation_type,
'offset': key_info['offset'],
'distance': self._key_distance(prev_key, current_key)
})
prev_key = current_key
return modulations
def _classify_modulation(self, key1, key2):
"""Classify the type of modulation"""
if key1 == key2:
return 'none'
# Check if relative major/minor
if key1 in self.relative_keys and self.relative_keys[key1] == key2:
return 'relative'
# Check circle of fifths distance
distance = self._key_distance(key1, key2)
if distance <= 1:
return 'close' # Adjacent on circle of fifths
elif distance <= 2:
return 'medium'
else:
return 'distant'
def _key_distance(self, key1, key2):
"""Calculate distance between keys on circle of fifths"""
try:
pos1 = self.circle_of_fifths.get(key1[0], 0)
pos2 = self.circle_of_fifths.get(key2[0], 0)
# Handle wraparound
distance = min(abs(pos1 - pos2), 12 - abs(pos1 - pos2))
# Add penalty for major/minor difference
if key1[1] != key2[1]:
distance += 0.5
return distance
except:
return 6 # Maximum distance
def _calculate_modulation_features(self, modulations, smoothed_keys, duration):
"""Calculate comprehensive modulation features"""
features = {}
# Basic counts
features['key_modulation_count'] = len(modulations)
features['modulation_rate'] = len(modulations) / duration if duration > 0 else 0
features['avg_modulations_per_minute'] = (len(modulations) / duration) * 60 if duration > 0 else 0
# Key diversity
unique_keys = set(key_info['key'] for key_info in smoothed_keys)
features['unique_keys'] = len(unique_keys)
# Key stability (percentage of time in most common key)
if smoothed_keys:
key_counts = Counter(key_info['key'] for key_info in smoothed_keys)
most_common_count = key_counts.most_common(1)[0][1]
features['key_stability'] = most_common_count / len(smoothed_keys)
else:
features['key_stability'] = 1.0
# Modulation characteristics
if modulations:
distances = [mod['distance'] for mod in modulations]
features['avg_modulation_distance'] = np.mean(distances)
features['max_modulation_distance'] = max(distances)
# Count modulation types
types = [mod['type'] for mod in modulations]
type_counts = Counter(types)
features['close_modulations'] = type_counts.get('close', 0)
features['medium_modulations'] = type_counts.get('medium', 0)
features['distant_modulations'] = type_counts.get('distant', 0)
else:
features['avg_modulation_distance'] = 0
features['max_modulation_distance'] = 0
features['close_modulations'] = 0
features['medium_modulations'] = 0
features['distant_modulations'] = 0
return features
# Helper methods
def _correlation(self, x, y):
"""Calculate Pearson correlation coefficient"""
if len(x) != len(y):
return 0
n = len(x)
if n == 0:
return 0
sum_x = sum(x)
sum_y = sum(y)
sum_xy = sum(x[i] * y[i] for i in range(n))
sum_x2 = sum(x[i] ** 2 for i in range(n))
sum_y2 = sum(y[i] ** 2 for i in range(n))
denominator = ((n * sum_x2 - sum_x ** 2) * (n * sum_y2 - sum_y ** 2)) ** 0.5
if denominator == 0:
return 0
return (n * sum_xy - sum_x * sum_y) / denominator
def _pc_to_name(self, pc):
"""Convert pitch class number to note name"""
names = ['C', 'C#', 'D', 'Eb', 'E', 'F', 'F#', 'G', 'Ab', 'A', 'Bb', 'B']
return names[pc % 12]
def _calculate_key_confidence(self, window_notes, key):
"""Calculate confidence score for a key assignment"""
if not key or not window_notes:
return 0.0
# Simple confidence based on how well the notes fit the key
tonic_pc = self.circle_of_fifths.get(key[0], 0)
# Key notes for major/minor
if key[1] == 'major':
key_pcs = [(tonic_pc + i) % 12 for i in [0, 2, 4, 5, 7, 9, 11]]
else:
key_pcs = [(tonic_pc + i) % 12 for i in [0, 2, 3, 5, 7, 8, 10]]
in_key = sum(1 for note in window_notes if note['pitch_class'] in key_pcs)
total = len(window_notes)
return in_key / total if total > 0 else 0.0
def empty_modulation_features(self):
"""Return empty/default modulation features"""
return {
'key_modulation_count': 0,
'modulation_rate': 0.0,
'avg_modulations_per_minute': 0.0,
'unique_keys': 1,
'key_stability': 1.0,
'avg_modulation_distance': 0.0,
'max_modulation_distance': 0.0,
'close_modulations': 0,
'medium_modulations': 0,
'distant_modulations': 0
}
def analyze_cadences(self, score, window_size, overlap, shared_data):
"""Analyze cadential patterns.
Cadences show how a composer resolves a phrase, or ends an idea.
In particular eras of classical music, cadences are quite predicatable.
For example more western religious music styles utilized plagal cadences
and authentic cadences to give a feeling of finality to a section of
music. We use three types for this excerise, but there are a whole
number of others that could be used for further analaysis. We also
count how many cadences there are as it shows the composer's tenden-
cies of resolution over time. How often one resolves a phrase should
measurably correlate to a composer's feeling of arriving at home base.
"""
features = {}
try:
# Use shared data
chords = shared_data.get('chords', [])
key_signature = shared_data.get('key_signature')
if len(chords) < 2 or not key_signature:
return self.empty_cadence_features()
# Detect cadences
authentic, plagal, deceptive = self._detect_cadences(chords, key_signature)
total_cadences = authentic + plagal + deceptive
# Calculate ratios
if total_cadences > 0:
features['authentic_cadence_ratio'] = authentic / total_cadences
features['plagal_cadence_ratio'] = plagal / total_cadences
features['deceptive_cadence_ratio'] = deceptive / total_cadences
else:
features['authentic_cadence_ratio'] = 0
features['plagal_cadence_ratio'] = 0
features['deceptive_cadence_ratio'] = 0
features['total_cadences'] = total_cadences
except Exception:
features = self.empty_cadence_features()
return features
def _detect_cadences(self, chords, key_signature):
# Optimize cadence detection with batch processing
batch_size = min(50, max(1, len(chords) // 4))
def analyze_chord_pairs(start_idx, end_idx):
authentic = 0
plagal = 0
deceptive = 0
for i in range(start_idx, min(end_idx, len(chords) - 1)):
try:
current_rn = roman.romanNumeralFromChord(chords[i], key_signature)
next_rn = roman.romanNumeralFromChord(chords[i+1], key_signature)
# V-I (authentic cadence)
if current_rn.scaleDegree == 5 and next_rn.scaleDegree == 1:
authentic += 1
# IV-I (plagal cadence)
elif current_rn.scaleDegree == 4 and next_rn.scaleDegree == 1:
plagal += 1
# V-vi (deceptive cadence)
elif current_rn.scaleDegree == 5 and next_rn.scaleDegree == 6:
deceptive += 1
except:
continue
return authentic, plagal, deceptive
# Define batch boundaries
batch_starts = list(range(0, len(chords) - 1, batch_size))
batch_ends = [start + batch_size for start in batch_starts]
# Process batches in parallel
authentic_cadences = 0
plagal_cadences = 0
deceptive_cadences = 0
with ThreadPoolExecutor() as executor:
results = list(executor.map(analyze_chord_pairs, batch_starts, batch_ends))
# Combine results
for auth, plag, dec in results:
authentic_cadences += auth
plagal_cadences += plag
deceptive_cadences += dec
return authentic_cadences, plagal_cadences, deceptive_cadences
def _identify_phrase_endings(self, score):
"""Identify likely phrase ending points.
A helper method to see if we can determine where phrases end.
This could be more comprehensive, but for now let's measure typical
phrase spanning 4 or 8 bars.
"""
# Simplified: assume phrase endings at measure boundaries with rests or longer notes
phrase_endings = []
try:
measures = score.parts[0].getElementsByClass('Measure') if score.parts else []
# Optimize for large measure sets
if len(measures) > 100:
# Only check measures at phrase boundaries (every 4th or 8th measure)
phrase_indices = [i for i in range(len(measures))
if (i + 1) % 4 == 0 or (i + 1) % 8 == 0]
# Process only relevant measures
for i in phrase_indices:
measure = measures[i]
chords_in_measure = measure.getElementsByClass(chord.Chord)
if chords_in_measure:
phrase_endings.append(chords_in_measure[-1])
else:
# For smaller sets, process normally
for i, measure in enumerate(measures):
if (i + 1) % 4 == 0 or (i + 1) % 8 == 0: # Assume 4 or 8-bar phrases
chords_in_measure = measure.getElementsByClass(chord.Chord)
if chords_in_measure:
phrase_endings.append(chords_in_measure[-1])
except:
pass
return phrase_endings
def empty_harmony_features(self):
return {
'total_chords': 0,
'unique_chords': 0,
'major_chord_ratio': 0,
'minor_chord_ratio': 0,
'diminished_chord_ratio': 0,
'augmented_chord_ratio': 0,
'avg_chord_inversion': 0,
'root_position_ratio': 0,
'progression_i_v_vi_iv_count': 0,
'progression_vi_iv_i_v_count': 0,
'progression_i_vi_iv_v_count': 0,
'progression_ii_v_i_count': 0,
'progression_i_iv_v_i_count': 0,
'progression_vi_ii_v_i_count': 0
}
def empty_dissonance_features(self):
return {
'avg_dissonance': 0,
'max_dissonance': 0,
'dissonance_variance': 0,
'tritone_frequency': 0
}
def empty_tonality_features(self):
return {
'tonic_frequency': 0,
'bass_tonic_frequency': 0,
'tonic_chord_ratio': 0,
'cadential_tonic_ratio': 0
}
def empty_modulation_features(self):
return {
'key_modulation_count': 0,
'modulation_rate': 0,
'unique_keys': 1,
'key_stability': 1,
'avg_modulations_per_minute': 0
}
def empty_cadence_features(self):
return {
'authentic_cadence_ratio': 0,
'plagal_cadence_ratio': 0,
'deceptive_cadence_ratio': 0,
'total_cadences': 0
}
5.2 RhythmAnalyzer:¶
RhythmAnalyzer – Purpose and Role in Feature Extraction
The RhythmAnalyzer extracts time-based rhythmic features that capture how often notes occur and how quickly harmony changes—two behaviors that strongly differentiate composers. These features complement pitch/harmony features by describing texture, momentum, and phrase pacing, all of which improve downstream composer classification.
Note: We also provide in-line code commenting to help detail each rhythmic feature and it's musical importance.
Rhythmic Components¶
Note Density (
analyze_note_density)- What it computes: For adaptively sized, overlapping windows across the piece, it calculates notes-per-beat (or per quarterLength) and summarizes with:
note_density_avg,note_density_variance,note_density_max,note_density_min- Peak metrics:
density_peak_count,density_peak_ratio(windows > 1.5× mean)
- How it’s implemented:
- Derives window boundaries from score duration (5–30 windows), ensuring stable coverage regardless of piece length.
- Uses
getElementsByOffsetfor fast window queries and parallelizes window processing. - Applies vectorized NumPy statistics for efficiency and consistency.
- Why it matters:
- Density reflects texture/complexity (e.g., Bach’s contrapuntal busyness vs. sparser lyricism).
- Peaks reveal climaxes or virtuosic passages; variance indicates dynamic contrast within a work—useful signals for stylistic fingerprints.
- What it computes: For adaptively sized, overlapping windows across the piece, it calculates notes-per-beat (or per quarterLength) and summarizes with:
Harmonic Rhythm (
analyze_harmonic_rhythm)- What it computes: Measures the rate and regularity of chord changes using chord onset offsets:
harmonic_rhythm_avg(mean time between chord changes)harmonic_rhythm_variance(consistency of changes)harmonic_rhythm_regularity(= 1 / (1 + variance)) as a normalized stability score
- How it’s implemented:
- Extracts chord offsets in one pass, computes consecutive differences with NumPy (
np.diff), and summarizes with vectorized stats.
- Extracts chord offsets in one pass, computes consecutive differences with NumPy (
- Why it matters:
- Composers and eras differ in pace of harmonic motion (e.g., Classical regularity vs. Romantic flexibility).
- Regular vs. irregular change patterns inform phrase structure, cadential planning, and emotional pacing, aiding model discrimination.
- What it computes: Measures the rate and regularity of chord changes using chord onset offsets:
Value for Model Prep/Train¶
These rhythmic descriptors add orthogonal information to pitch and harmony features, enabling the model to learn not just what harmonies are used, but how quickly and densely musical events happen. The combination improves class separability, reduces over-reliance on pitch-only cues, in an effort to improve our LSTM/CNN training.
class RhythmAnalyzer:
def __init__(self, np_module):
self.np = np_module
def analyze_note_density(self, score, window_size, overlap, shared_data):
"""Analyze density of notes over time.
A note density analysis provides an measurement of how many notes
occur within a given segment of musical time. This is useful in
understanding the overall sliding scale of simplicitiy and complexity
of the composition. Some composers might change how 'dense' a
section or a composition is to express certain emotive qualities,
a very useful contributer to our feature analysis.
"""
features = {}
try:
# Use shared data
duration = shared_data.get('total_duration', 0)
if duration == 0:
return self.empty_density_features()
# Use adaptive window sizing for more consistent results
step_size = window_size * (1 - overlap)
# Calculate optimal number of windows based on score duration
num_windows = max(5, min(30, int(duration / step_size)))
adjusted_step = duration / num_windows
# Pre-calculate all window boundaries
window_boundaries = []
for i in range(num_windows):
start_offset = i * adjusted_step
end_offset = min(start_offset + window_size, duration)
window_boundaries.append((start_offset, end_offset))
# Analyze windows in parallel
densities = self._analyze_density_windows(score, window_boundaries)
if densities:
# Use numpy for vectorized statistics
densities_array = self.np.array(densities)
# Calculate statistics
features['note_density_avg'] = float(self.np.mean(densities_array))
features['note_density_variance'] = float(self.np.var(densities_array))
features['note_density_max'] = float(self.np.max(densities_array))
features['note_density_min'] = float(self.np.min(densities_array))
# Find density peaks efficiently using vectorized operations
mean_density = self.np.mean(densities_array)
peak_threshold = mean_density * 1.5
peaks = int(self.np.sum(densities_array > peak_threshold))
features['density_peak_count'] = peaks
features['density_peak_ratio'] = peaks / len(densities_array) if len(densities_array) > 0 else 0
else:
features.update(self.empty_density_features())
except Exception:
features = self.empty_density_features()
return features
def _analyze_density_windows(self, score, window_boundaries):
# Process windows in parallel with efficient offset querying
def analyze_window(boundary):
start_offset, end_offset = boundary
try:
window_notes = score.flat.notes.getElementsByOffset(
start_offset, end_offset, includeEndBoundary=False
)
note_count = len(window_notes)
window_duration = end_offset - start_offset
if window_duration > 0:
return note_count / window_duration
except:
pass
return 0
# Use ThreadPoolExecutor for parallel processing
with ThreadPoolExecutor() as executor:
densities = list(executor.map(analyze_window, window_boundaries))
# Filter out any None values
densities = [d for d in densities if d is not None]
return densities
def analyze_harmonic_rhythm(self, score, window_size, overlap, shared_data):
"""Analyze the rate of harmonic change.
Harmonic change is the rate of variance in chordal structures measured
over time. A composer who moves from chord to chord quickly might not
only be indicative of tempo, but the harmonic expressiveness of a
passage of music. For example changing chords often in a slow song
might indicate a specific feeling of excited progression. Conversely,
a fast tempo composition with less chord changes indicates a potentially
more stagnant mood.
"""
features = {}
try:
# Use shared data
chords = shared_data.get('chords', [])
if len(chords) < 2:
return self.empty_rhythm_features()
# Efficient chord offset extraction using list comprehension
offsets = [float(c.offset) for c in chords]
# Convert to numpy array for vectorized operations
offsets_array = self.np.array(offsets)
# Calculate differences between consecutive offsets
chord_changes = self.np.diff(offsets_array)
if len(chord_changes) > 0:
# Calculate statistics efficiently using numpy
avg_change = float(self.np.mean(chord_changes))
variance = float(self.np.var(chord_changes))
features['harmonic_rhythm_avg'] = avg_change
features['harmonic_rhythm_variance'] = variance
features['harmonic_rhythm_regularity'] = 1 / (1 + variance) if variance != 0 else 0
else:
features.update(self.empty_rhythm_features())
except Exception:
features = self.empty_rhythm_features()
return features
def empty_density_features(self):
return {
'note_density_avg': 0,
'note_density_variance': 0,
'note_density_max': 0,
'note_density_min': 0,
'density_peak_count': 0,
'density_peak_ratio': 0
}
def empty_rhythm_features(self):
return {
'harmonic_rhythm_avg': 0,
'harmonic_rhythm_variance': 0,
'harmonic_rhythm_regularity': 0
}
5.3 MelodyAnalyzer:¶
The MelodyAnalyzer captures melodic movement and voice-leading behavior—how lines move from note to note; an essential stylistic cue in classical composition. These descriptors complement harmony and rhythm by quantifying the smoothness vs. angularity of melodic writing, which varies meaningfully across composers and eras.
Note: We also provide in-line code commenting to help detail our melodic features and the musical importance.
Melodic Component¶
- Voice Leading (
analyze_voice_leading)- What it computes: For each musical part (voice), measures how often successive notes move by step (≤ 2 semitones) versus leap (> 2 semitones), then aggregates across parts:
step_motion_ratio– proportion of stepwise intervalsleap_motion_ratio– proportion of leaping intervalsvoice_leading_smoothness– alias ofstep_motion_ratioas a single smoothness indicator
- How it’s implemented:
- Pulls parts from shared data, flattens notes per part, converts pitches to MIDI, and uses NumPy
difffor vectorized interval calculations. - Counts steps/leaps efficiently and sums results across parts; returns stable defaults when parts are missing or too short.
- Pulls parts from shared data, flattens notes per part, converts pitches to MIDI, and uses NumPy
- Why it matters:
- Composers differ in melodic contour—e.g., Bach often features stepwise contrapuntal motion, while others may use wider arpeggiated leaps.
- Smoothness vs. angularity informs expressive character, vocal idiom, and period style, providing discriminative features for composer classification.
- What it computes: For each musical part (voice), measures how often successive notes move by step (≤ 2 semitones) versus leap (> 2 semitones), then aggregates across parts:
Value for Model Prep/Train¶
By encoding the micro-level interval behavior of melodic lines, the MelodyAnalyzer supplies features that are orthogonal to harmony and rhythm, improving class separability and giving LSTM/CNN models richer musical context for learning stylistic signatures.
class MelodyAnalyzer:
def __init__(self, np_module):
self.np = np_module
def analyze_voice_leading(self, score, window_size, overlap, shared_data):
"""Analyze voice leading patterns.
Voice leading is very important consideration in classical music analysis.
How a series of melodic notes 'evolve' over time directly coresponds
to the stylistic tendencies of each composer. Compositions that
have a more step-wise motion (from one note to the nearest neightboring
note) will be considered less abrupt and provide more scalar motion.
Consecutive notes that jump (called leaping) could be more arpeggiated
in nature and sound less smooth. Although voice leading is more complex
than this, we believe this will help our classification analysis by
attempting to extract the overall 'smoothness' of the melodic voicing.
"""
features = {}
try:
# Use shared data
parts = shared_data.get('parts', [])
if not parts:
return self.empty_voice_features()
# Process each part in parallel
step_motions, leap_motions, total_motions = self._analyze_parts(parts)
# Calculate ratios
if total_motions > 0:
features['step_motion_ratio'] = step_motions / total_motions
features['leap_motion_ratio'] = leap_motions / total_motions
features['voice_leading_smoothness'] = features['step_motion_ratio']
else:
features.update(self.empty_voice_features())
except Exception:
features = self.empty_voice_features()
return features
def _analyze_parts(self, parts):
def analyze_part(part):
try:
if not hasattr(part, 'flat'):
return 0, 0, 0
notes = [n for n in part.flat.notes if hasattr(n, 'pitch')]
if len(notes) < 2:
return 0, 0, 0
# Extract pitches efficiently
pitches = [n.pitch.midi for n in notes]
if not pitches:
return 0, 0, 0
pitch_array = self.np.array(pitches)
# Calculate intervals using vectorized operations
intervals = self.np.abs(self.np.diff(pitch_array))
# Count step vs leap motions efficiently
steps = int(self.np.sum(intervals <= 2))
leaps = int(self.np.sum(intervals > 2))
return steps, leaps, len(intervals)
except Exception as e:
print(f"Error analyzing part: {e}")
return 0, 0, 0
# Check if parts list is valid
if not parts or not isinstance(parts, list):
return 0, 0, 0
# Process parts in sequential mode for debugging
part_results = []
for part in parts:
part_results.append(analyze_part(part))
# Combine results
step_motions = sum(steps for steps, _, _ in part_results)
leap_motions = sum(leaps for _, leaps, _ in part_results)
total_motions = sum(total for _, _, total in part_results)
return step_motions, leap_motions, total_motions
def empty_voice_features(self):
return {
'step_motion_ratio': 0,
'leap_motion_ratio': 0,
'voice_leading_smoothness': 0
}
5.4 StructureAnalyzer:¶
The StructureAnalyzer captures formal organization in a piece includinf phrase sizing, sectional regularity, and melodic repetition. These descriptors complement pitch, harmony, rhythm, and melody by extracting how musical properties are grouped and reused, which is a strong stylistic cue for composer classification.
Structural Components¶
Musical Structure (
analyze_musical_structure)- What it computes:
total_measures– total count of measures in the first part (fast proxy for form length).phrase_structure_regularity– binary flag indicating if the piece divides cleanly into common phrase lengths (4/8/16-bar units).estimated_phrase_length– best-fitting phrase unit among {4, 8, 16}, defaulting to 8 if none fit.melodic_repetition_count– number of recurring 4-note patterns.repetition_density– repetitions per measure (melodic_repetition_count / total_measures).
- How it’s implemented:
- Efficiently fetches measures from the first part and checks divisibility by canonical phrase lengths.
- Calls
_extract_melodic_patternsto count repeated 4-note pitch tuples and normalizes by measure count. - Returns safe defaults via
empty_structure_features()for edge cases (e.g., no measures).
- Why it matters:
- Regular 4/8/16-bar phrasing is period- and genre-typical (e.g., Classical clarity vs. freer Romantic phrasing).
- Repetition density reflects motivic economy vs. developmental variety, aiding stylistic discrimination.
- What it computes:
Melodic Pattern Mining (
_extract_melodic_patterns)- What it computes: A dictionary of 4-note pitch patterns → occurrence counts, later aggregated into repetition metrics.
- How it’s implemented:
- Extracts pitches from
score.flat.notesonce; uses tuple windows of length 4. - Adaptive strategy:
- For small/medium scores: single-pass sequential counting (cache-friendly).
- For large scores (>1000 notes): chunked parallel processing with overlapping boundaries to avoid missing patterns spanning chunks; merges partial dictionaries efficiently.
- Extracts pitches from
- Why it matters:
- Frequent short patterns indicate motivic repetition (e.g., classical periodicity), while sparse repetition suggests through-composition or developmental writing—both are stylistically meaningful.
Value for Model Prep/Train¶
Structural signals—phrase regularity and motivic reuse—are orthogonal to pitch/rhythm/harmony features and encode the composer’s macro-level organization. Including them enriches the feature set, improves class separability, and provides interpretable levers (e.g., “regular phrasing + high repetition density”) that help LSTM/CNN models learn consistent stylistic signatures.
class StructureAnalyzer:
def __init__(self, np_module):
self.np = np_module
def analyze_musical_structure(self, score, window_size, overlap, shared_data):
features = {}
try:
# Get measures efficiently
measures = score.parts[0].getElementsByClass('Measure') if score.parts else []
total_measures = len(measures)
# Fast phrase analysis with early return for edge cases
if total_measures == 0:
return self.empty_structure_features()
# phrase length analysis
phrase_lengths = [4, 8, 16]
best_phrase_fit = 0
# Check divisibility efficiently
for length in phrase_lengths:
if total_measures % length == 0:
best_phrase_fit = length
break
features['phrase_structure_regularity'] = 1 if best_phrase_fit > 0 else 0
features['estimated_phrase_length'] = best_phrase_fit if best_phrase_fit > 0 else 8
features['total_measures'] = total_measures
# Extract melodic patterns
note_patterns = self._extract_melodic_patterns(score)
# Count repetitions efficiently
pattern_repetitions = sum(1 for count in note_patterns.values() if count > 1)
features['melodic_repetition_count'] = pattern_repetitions
features['repetition_density'] = pattern_repetitions / total_measures if total_measures > 0 else 0
except Exception:
features = self.empty_structure_features()
return features
def _extract_melodic_patterns(self, score):
patterns = defaultdict(int)
try:
notes = [n for n in score.flat.notes if hasattr(n, 'pitch')]
pattern_length = 4 # 4-note patterns
# Early return for short note sequences
if len(notes) < pattern_length:
return patterns
# Extract all pitches at once for better performance
pitches = [n.pitch.midi for n in notes]
# Adaptive parallelization based on data size
if len(notes) > 1000:
# For very large sets, use parallel processing with optimized chunk size
chunk_size = max(pattern_length * 20, len(notes) // (os.cpu_count() or 4))
# Create overlapping chunks to ensure we catch patterns at chunk boundaries
chunks = []
for i in range(0, len(pitches) - pattern_length + 1, chunk_size - pattern_length + 1):
end_idx = min(i + chunk_size, len(pitches))
if end_idx - i >= pattern_length:
chunks.append((i, end_idx))
def process_chunk(chunk_range):
start_idx, end_idx = chunk_range
chunk_patterns = defaultdict(int)
# Process patterns within this chunk
for i in range(start_idx, end_idx - pattern_length + 1):
pattern = tuple(pitches[i:i+pattern_length])
chunk_patterns[pattern] += 1
return dict(chunk_patterns)
# Process chunks in parallel
with ThreadPoolExecutor() as executor:
chunk_results = list(executor.map(process_chunk, chunks))
# Merge results efficiently
for chunk_pattern in chunk_results:
for pattern, count in chunk_pattern.items():
patterns[pattern] += count
else:
# For smaller sets, use efficient sequential processing
for i in range(len(pitches) - pattern_length + 1):
pattern = tuple(pitches[i:i+pattern_length])
patterns[pattern] += 1
except:
pass
return patterns
def empty_structure_features(self):
return {
'phrase_structure_regularity': 0,
'estimated_phrase_length': 8,
'total_measures': 0,
'melodic_repetition_count': 0,
'repetition_density': 0
}
End-to-End Feature Extraction & Sequencing Pipeline
The next blocks run our full pipeline to create model-ready datasets from filtered and feature-extracted MIDI files. It covers base musical features, symbolic note sequences for LSTM/CNNs, advanced harmonic features, and on-disk caching for ease of reproducibility and speed.
Setup & File List
- Initialize
FeatureExtractor, collectmidi_pathsfrommidi_df, and gate everything withEXTRACT_FEATURESso the run can be toggled between build and load-from-cache modes.
- Initialize
Base Musical Features (Parallel)
MidiProcessor.extract_musical_features_parallel(midi_paths, n_jobs=OPTIMAL_WORKERS)computes per-file descriptors (pitch stats, intervals, durations, tempo, key, chords/rests, etc.) using a thread pool and a progress bar.- Results are assembled into
features_dfand augmented withcomposer,filename, andfile_path.
Persist Base Features
- Save
features_dftoMUSICAL_FEATURES_DF_PATH(pickle). - Why: Fast reloads, reproducible experiments, and no re-parsing on subsequent runs.
- Save
Note Extraction & Sequence Building (for Sequence Models)
MidiProcessor.extract_notes_from_midi_parallel(..., max_notes=500)collects compact symbolic note streams per file (cap keeps memory predictable).create_note_sequences(..., sequence_length=100)builds a global vocabulary (note_to_int,unique_notes) and generates fixed-length windows for deep models.- Balancing: At most 50 sequences per file are used to limit dominance by large files and mitigate class imbalance at the sequence level.
Labeling & Serialization for Training
- Map
TARGET_COMPOSERSto integers (composer_to_int), createsequence_labelsaligned to the sequences, and save:- Sequences →
NOTE_SEQUENCES_PATH(.npy) - Labels →
NOTE_SEQUENCES_LABELS_PATH(.npy) - Mappings (
note_to_int,unique_notes,composer_to_int,int_to_composer) →NOTE_MAPPING_PATH(pickle).
- Sequences →
- Why: Clean separation of data/labels, stable vocabularies, and drop-in loading during model training.
- Map
Advanced Harmonic Feature Set (Batch)
feature_extractor.extract_features_batch(...)computes higher-level harmony/tonality metrics (e.g., progressions, cadence ratios, modulation stats).- Pack into
harmonic_df, append identifiers, and save toHARMONIC_FEATURES_DF_PATH(pickle). - Why: Adds musically meaningful, composer-specific signals beyond basic stats and raw note tokens.
Cache-Aware Reloading
- If
EXTRACT_FEATURESis False, the code loads existing pickles (MUSICAL_FEATURES_DF_PATH,HARMONIC_FEATURES_DF_PATH) with clear messaging. - Why: Rapid iteration, avoids duplicate compute, and ensures consistent datasets across experiments.
- If
Outcome:
We end up with (a) a tabular feature matrix, (b) fixed-length note sequences and labels for LSTM/CNN training, and (c) a musically rich harmonic feature table—each cached for fast reuse. The caps (max_notes=500, ≤50 sequences/file) and composer label mapping help control memory, reduce imbalance, and keep the training set standardized.
class FeatureExtractor:
def __init__(self):
# Force GPU backend (CuPy) if available, else fallback to NumPy
try:
import cupy as cp
self.np = cp
self.has_gpu = True
print("CuPy GPU backend enabled for feature extraction.")
except ImportError:
import numpy as np
self.np = np
self.has_gpu = False
print("CuPy not available, using NumPy (CPU) backend.")
self.harmony_analyzer = HarmonyAnalyzer(self.np)
self.structure_analyzer = StructureAnalyzer(self.np)
self.rhythm_analyzer = RhythmAnalyzer(self.np)
self.melody_analyzer = MelodyAnalyzer(self.np)
self.score_cache = {}
def _extract_shared_data(self, score):
try:
if hasattr(score, 'duration') and score.duration is not None:
total_duration = float(score.duration.quarterLength)
else:
all_elements = list(score.flat.notesAndRests)
if all_elements and self.has_gpu:
offsets = self.np.array([float(el.offset) for el in all_elements])
durations = self.np.array([float(el.duration.quarterLength) for el in all_elements])
total_duration = float(self.np.max(offsets + durations))
else:
total_duration = sum(float(el.offset + el.duration.quarterLength) for el in all_elements) if all_elements else 0
try:
key_signature = score.analyze('key')
except Exception:
key_signature = key.Key('C')
chords = list(score.flat.getElementsByClass(chord.Chord))
notes = list(score.flat.notes)
parts = score.parts if hasattr(score, 'parts') and score.parts else [score]
return {
'chords': chords,
'notes': notes,
'parts': parts,
'total_duration': total_duration,
'key_signature': key_signature
}
except Exception as e:
print(f"Error in _extract_shared_data: {e}")
return {
'chords': [],
'notes': [],
'parts': [score],
'total_duration': 0,
'key_signature': key.Key('C')
}
def _run_parallel_analysis(self, score, window_size, overlap, shared_data):
features = {}
analysis_tasks = {
'harmony': (self.harmony_analyzer, 'analyze_chords_and_progressions'),
'dissonance': (self.harmony_analyzer, 'analyze_dissonance'),
'tonality': (self.harmony_analyzer, 'analyze_tonality'),
'modulation': (self.harmony_analyzer, 'analyze_key_modulations'),
'density': (self.rhythm_analyzer, 'analyze_note_density'),
'rhythm': (self.rhythm_analyzer, 'analyze_harmonic_rhythm'),
'voice': (self.melody_analyzer, 'analyze_voice_leading'),
'structure': (self.structure_analyzer, 'analyze_musical_structure'),
'cadence': (self.harmony_analyzer, 'analyze_cadences')
}
for name, (analyzer, method) in analysis_tasks.items():
try:
analyzer_method = getattr(analyzer, method)
result = analyzer_method(score, window_size, overlap, shared_data)
features.update(result)
except Exception as e:
print(f"Error in {name} analysis: {e}")
empty_method = f"empty_{name}_features"
if hasattr(analyzer, empty_method):
features.update(getattr(analyzer, empty_method)())
return features
def extract_harmonic_features(self, midi_path, window_size=4.0, overlap=0.5):
"""
Extract harmonic and structural features from our MIDI file dataset.
Arguments:
midi_path (str): Path to the MIDI file
window_size (float): Size of analysis window in quarter notes
overlap (float): Overlap between windows (0-1)
Returns:
dict: Dictionary containing all the extracted harmonic features
"""
try:
cache_key = f"{midi_path}_{window_size}_{overlap}"
if cache_key in self.score_cache:
score = self.score_cache[cache_key]
else:
# Use faster parsing: only parse first part for large files
score = converter.parse(midi_path, quantizePost=True)
if hasattr(score, 'parts') and len(score.parts) > 1:
score = score.parts[0] # Only analyze first part for speed
self.score_cache[cache_key] = score
if len(self.score_cache) > 100:
self.score_cache.clear()
shared_data = self._extract_shared_data(score)
# Reduce window_size and overlap for faster analysis
features = self._run_parallel_analysis(score, window_size=8.0, overlap=0.2, shared_data=shared_data)
if self.has_gpu:
try:
self.np.cuda.Stream.null.synchronize()
except:
pass
return features
except Exception as e:
print(f"Error extracting features from {midi_path}: {e}")
return self._empty_features()
def extract_features_batch(self, midi_paths, n_jobs=4, window_size=4.0, overlap=0.5):
from concurrent.futures import ThreadPoolExecutor, as_completed
from tqdm import tqdm
optimal_jobs = min(n_jobs, os.cpu_count() or 4)
if len(midi_paths) < optimal_jobs * 2:
optimal_jobs = max(1, len(midi_paths) // 2)
# Increase batch size for fewer thread launches
batch_size = max(8, len(midi_paths) // optimal_jobs)
results = [None] * len(midi_paths)
batches = self._create_balanced_batches(midi_paths, optimal_jobs)
pbar = tqdm(total=len(midi_paths), desc="Extracting features (GPU)")
with ThreadPoolExecutor(max_workers=optimal_jobs) as executor:
futures = [executor.submit(self._process_batch, batch) for batch in batches]
for future in as_completed(futures):
try:
batch_results = future.result()
for idx, features in batch_results.items():
results[idx] = features
pbar.update(len(batch_results))
if self.has_gpu:
try:
self.np.cuda.Stream.null.synchronize()
except:
pass
except Exception as e:
print(f"\nError processing batch: {e}")
pbar.close()
if self.has_gpu:
try:
self.np.cuda.runtime.deviceSynchronize()
self.score_cache.clear()
except:
pass
return results
def _create_balanced_batches(self, midi_paths, n_jobs):
if len(midi_paths) <= n_jobs:
return [(i, [path]) for i, path in enumerate(midi_paths)]
else:
batch_size = max(1, len(midi_paths) // n_jobs)
batches = []
for i in range(0, len(midi_paths), batch_size):
batch_paths = midi_paths[i:i+batch_size]
batch_indices = list(range(i, min(i+batch_size, len(midi_paths))))
batches.append((batch_indices, batch_paths))
return batches
def _process_batch(self, batch_data):
if isinstance(batch_data[0], int):
idx, path = batch_data
return {idx: self.extract_harmonic_features(path)}
else:
batch_indices, batch_paths = batch_data
batch_results = {}
for idx, path in zip(batch_indices, batch_paths):
try:
features = self.extract_harmonic_features(path)
batch_results[idx] = features
except Exception:
batch_results[idx] = self._empty_features()
if self.has_gpu and len(batch_results) % 2 == 0:
try:
self.np.cuda.Stream.null.synchronize()
except:
pass
return batch_results
def _empty_features(self):
features = {}
try:
features.update(self.harmony_analyzer.empty_harmony_features())
features.update(self.harmony_analyzer.empty_dissonance_features())
features.update(self.harmony_analyzer.empty_tonality_features())
features.update(self.harmony_analyzer.empty_modulation_features())
features.update(self.harmony_analyzer.empty_cadence_features())
features.update(self.rhythm_analyzer.empty_density_features())
features.update(self.rhythm_analyzer.empty_rhythm_features())
features.update(self.melody_analyzer.empty_voice_features())
features.update(self.structure_analyzer.empty_structure_features())
except Exception as e:
print(f"Error creating empty features: {e}")
features = {"error": "Could not generate empty features"}
return features
# Initialize the FeatureExtractor
feature_extractor = FeatureExtractor()
midi_paths = midi_df['file_path'].tolist()
if EXTRACT_FEATURES:
# Get the list of file paths from the filtered dataframe
print(f"Extracting musical features from {len(midi_paths)} MIDI files...")
# Extract base features with parallel processing and progress bar
base_features = MidiProcessor.extract_musical_features_parallel(
midi_paths,
n_jobs=OPTIMAL_WORKERS # Use optimal number of workers
)
# Create a DataFrame with the extracted features
features_df = pd.DataFrame(base_features)
# Add composer and filename information
features_df['composer'] = midi_df['composer'].values
features_df['filename'] = midi_df['filename'].values
features_df['file_path'] = midi_df['file_path'].values
# Display information about the extracted features
print(f"\nExtracted {len(features_df)} feature sets")
print(f"Number of features: {len(features_df.columns) - 3}")
display(features_df.head())
# Save to pickle for faster access later
# Ensure the directory exists before saving
os.makedirs(os.path.dirname(MUSICAL_FEATURES_DF_PATH), exist_ok=True)
features_df.to_pickle(MUSICAL_FEATURES_DF_PATH)
print(f"Features saved to '{MUSICAL_FEATURES_DF_PATH}'")
else:
print("Feature extraction is disabled. Musical Features will be extracted from the existing data files.")
CuPy not available, using NumPy (CPU) backend. Feature extraction is disabled. Musical Features will be extracted from the existing data files.
if EXTRACT_FEATURES:
# Extract notes from MIDI files
print("\nExtracting notes from MIDI files for sequence modeling...")
notes_list = MidiProcessor.extract_notes_from_midi_parallel(
midi_paths,
max_notes=500, # Limit notes per file for memory efficiency
n_jobs=OPTIMAL_WORKERS
)
# Add notes to the dataframe
features_df['notes'] = notes_list
# Create note sequences for modeling
all_notes_list = features_df['notes'].tolist()
sequence_length = 100
note_sequences, note_to_int, unique_notes = MidiProcessor.create_note_sequences(all_notes_list, sequence_length=sequence_length)
# Create labels for sequences based on the originating files
sequence_labels = []
sequence_composers = []
sequence_counts = []
# Track sequences per file
current_idx = 0
for idx, row in features_df.iterrows():
notes = row['notes']
composer = row['composer']
filename = row['filename']
# Count potential sequences from this file
if len(notes) >= sequence_length:
potential_sequences = len(notes) - sequence_length + 1
actual_sequences = min(potential_sequences, 50) # Cap at 50 sequences per file for balance
else:
actual_sequences = 0
# Add labels for each sequence
sequence_composers.extend([composer] * actual_sequences)
sequence_counts.append(actual_sequences)
current_idx += actual_sequences
print(f"Created {len(sequence_composers)} labeled sequences")
# Create a mapping from composer to integer label
composer_to_int = {composer: i for i, composer in enumerate(TARGET_COMPOSERS)}
sequence_labels = [composer_to_int[composer] for composer in sequence_composers]
# Save the sequences, labels and mappings for model training
print(note_sequences)
np.save(NOTE_SEQUENCES_PATH, note_sequences[:len(sequence_labels)])
print(f"Note sequences saved to '{NOTE_SEQUENCES_PATH}'")
print(f"Note sequences labels shape: {np.array(sequence_labels).shape}")
np.save(NOTE_SEQUENCES_LABELS_PATH, np.array(sequence_labels))
print(f"Note sequence labels saved to '{NOTE_SEQUENCES_LABELS_PATH}'")
# Save mappings for later use
note_mapping = {
'note_to_int': note_to_int,
'unique_notes': unique_notes,
'composer_to_int': composer_to_int,
'int_to_composer': {i: composer for composer, i in composer_to_int.items()}
}
print(note_mapping)
with open(NOTE_MAPPING_PATH, 'wb') as f:
pickle.dump(note_mapping, f)
print(f"Note mappings saved to '{NOTE_MAPPING_PATH}'")
else:
print("Feature extraction is disabled. Notes Features will be extracted from the existing data files.")
Feature extraction is disabled. Notes Features will be extracted from the existing data files.
if EXTRACT_FEATURES:
# Extract harmonic features
print("\nExtracting harmonic features...")
harmonic_features = feature_extractor.extract_features_batch(
midi_paths,
n_jobs=OPTIMAL_WORKERS
)
# Create a separate dataframe for harmonic features
harmonic_df = pd.DataFrame(harmonic_features)
harmonic_df['composer'] = midi_df['composer'].values
harmonic_df['filename'] = midi_df['filename'].values
harmonic_df['file_path'] = midi_df['file_path'].values
# Save harmonic features to pickle
harmonic_df.to_pickle(HARMONIC_FEATURES_DF_PATH)
print(f"Harmonic features saved to '{HARMONIC_FEATURES_DF_PATH}'")
# Show a sample of the extracted features
display(harmonic_df.head())
else:
print("Harmonic feature extraction is disabled. Harmonic Features will be extracted from the existing data files.")
Harmonic feature extraction is disabled. Harmonic Features will be extracted from the existing data files.
if not EXTRACT_FEATURES:
if os.path.exists(MUSICAL_FEATURES_DF_PATH):
print(f"Musical features already extracted. Loading from '{MUSICAL_FEATURES_DF_PATH}'")
features_df = pd.read_pickle(MUSICAL_FEATURES_DF_PATH)
else:
print(f"Musical features not found at '{MUSICAL_FEATURES_DF_PATH}'. Please run feature extraction first.")
if os.path.exists(HARMONIC_FEATURES_DF_PATH):
print(f"Harmonic features already extracted. Loading from '{HARMONIC_FEATURES_DF_PATH}'")
harmonic_df = pd.read_pickle(HARMONIC_FEATURES_DF_PATH)
else:
print(f"Harmonic features not found at '{HARMONIC_FEATURES_DF_PATH}'. Please run feature extraction first.")
else:
print("Feature extraction is enabled. Musical Features and Harmonic Features have been extracted and saved.")
Musical features already extracted. Loading from 'data/features/musical_features_df.pkl' Harmonic features already extracted. Loading from 'data/features/harmonic_features_df.pkl'
Notice the use of "if EXTRACT_FEATURES" in the code above. This conditional allows us to cache extracted features in Pickle files, eliminating a need to re-run the feature extraction process each time we train or evaluate our models.
def plot_boxplots_and_violin(features_df, target_composers, colors):
fig, axs = plt.subplots(1, 3, figsize=(20, 5.6))
# 1. Distribution of total notes per composer
sns.boxplot(x='composer', y='total_notes', data=features_df, palette=env_config.color_pallete, ax=axs[0])
axs[0].set_title('Total Notes per Composer')
axs[0].set_xlabel('Composer')
axs[0].set_ylabel('Total Notes')
# 2. Distribution of average pitch per composer
sns.boxplot(x='composer', y='avg_pitch', data=features_df, palette=env_config.color_pallete, ax=axs[1])
axs[1].set_title('Average Pitch per Composer')
axs[1].set_xlabel('Composer')
axs[1].set_ylabel('Average Pitch (MIDI Number)')
# 3. Distribution of tempo per composer
sns.violinplot(x='composer', y='tempo', data=features_df, palette=env_config.color_pallete, ax=axs[2])
axs[2].set_title('Tempo per Composer')
axs[2].set_xlabel('Composer')
axs[2].set_ylabel('Tempo (BPM)')
plt.tight_layout()
plt.show()
def plot_correlation_heatmap(features_df):
plt.figure(figsize=(16, 10))
corr = features_df.select_dtypes(include=[np.number]).corr()
sns.heatmap(corr, annot=True, fmt=".2f", cmap="coolwarm", square=True)
plt.title("Correlation Heatmap of Musical Features")
plt.tight_layout()
plt.show()
def plot_3d_scatter(features_df, target_composers, colors):
fig_3d = plt.figure(figsize=(12, 8))
ax = fig_3d.add_subplot(111, projection='3d')
for composer in target_composers:
subset = features_df[features_df['composer'] == composer]
ax.scatter(subset['avg_pitch'], subset['tempo'], subset['total_notes'],
label=composer, alpha=0.7, s=50, color=colors[composer])
ax.set_xlabel('Average Pitch')
ax.set_ylabel('Tempo (BPM)')
ax.set_zlabel('Total Notes')
ax.set_title('3D Scatter: Pitch, Tempo, Notes by Composer')
ax.legend()
plt.tight_layout()
plt.show()
def plot_top_chords(features_df):
all_chords = [chord for sublist in features_df['chord_types'] for chord in sublist]
top_chords = Counter(all_chords).most_common(10)
chord_names, chord_counts = zip(*top_chords)
plt.figure(figsize=(10, 6))
sns.barplot(x=list(chord_names), y=list(chord_counts), palette=env_config.color_pallete,)
plt.title('Top 10 Chord Types in Dataset')
plt.ylabel('Count')
plt.xlabel('Chord Type')
plt.xticks(rotation=30)
plt.tight_layout()
plt.show()
def plot_rest_ratio(features_df, colors):
plt.figure(figsize=(10, 6))
rest_means = features_df.groupby('composer')['rest_ratio'].mean().reset_index()
sns.barplot(x='composer', y='rest_ratio', data=rest_means, palette=env_config.color_pallete,)
plt.title('Average Rest Ratio per Composer')
plt.xlabel('Composer')
plt.ylabel('Average Rest Ratio')
# Add numerical values on top of each bar
for i, value in enumerate(rest_means['rest_ratio']):
plt.text(i, value + 0.002, f'{value:.4f}', ha='center')
plt.tight_layout()
plt.show()
def plot_pairplot(features_df, colors):
# No direct figsize for pairplot, but we'll use the figure.set_size_inches method
g = sns.pairplot(features_df, vars=['avg_pitch', 'tempo', 'pitch_range', 'rest_ratio'],
hue='composer', palette=env_config.color_pallete, diag_kind='kde', plot_kws={'alpha':0.6, 's':40})
g.fig.set_size_inches(20, 20)
plt.suptitle('Pairplot of Musical Features by Composer', y=1.02)
plt.show()
def plot_midi_samples(midi_df, sample_indices, target_composers):
for i, idx in enumerate(sample_indices):
sample_path = midi_df.loc[idx, 'file_path']
try:
multitrack = pypianoroll.read(sample_path)
pr = multitrack.tracks[0].pianoroll
pitch_sum = pr.sum(axis=0)
nonzero_pitches = np.where(pitch_sum > 0)[0]
if len(nonzero_pitches) > 0:
min_pitch = max(nonzero_pitches[0] - 2, 0)
max_pitch = min(nonzero_pitches[-1] + 2, 127)
else:
min_pitch, max_pitch = 21, 108
fig = plt.figure(figsize=(20, 5))
ax = fig.add_subplot(111)
ax.imshow(
multitrack.tracks[0].pianoroll.T,
aspect='auto',
origin='lower',
interpolation='nearest',
cmap='Blues'
)
ax.set_ylim(min_pitch, max_pitch)
plt.title(f"{target_composers[i]}: {midi_df.loc[idx, 'filename']}")
plt.tight_layout()
plt.show()
except Exception as e:
print(f"Error processing MIDI file {midi_df.loc[idx, 'filename']}: {str(e)}")
continue
def plot_spectrograms(midi_df, target_composers):
plt.figure(figsize=(20, 12))
for i, composer in enumerate(target_composers, 1):
composer_files = midi_df[midi_df['composer'] == composer]['file_path'].values
if len(composer_files) == 0:
print(f"No files found for composer {composer}")
continue
# Try multiple files if one fails
for _ in range(min(3, len(composer_files))): # Try up to 3 files
sample_file = np.random.choice(composer_files)
try:
pm = pretty_midi.PrettyMIDI(sample_file)
audio_data = pm.synthesize(fs=22050)
plt.subplot(2, 2, i)
mel_spec = librosa.feature.melspectrogram(y=audio_data, sr=22050, n_mels=128, fmax=8000)
mel_spec_db = librosa.power_to_db(mel_spec, ref=np.max)
librosa.display.specshow(mel_spec_db, y_axis='mel', x_axis='time', fmax=8000, cmap='coolwarm')
plt.colorbar(format='%+2.0f dB')
plt.title(f'Mel-spectrogram: {composer}')
break # If successful, break the loop
except Exception as e:
print(f"Error processing spectrogram for {composer} file {sample_file}: {str(e)}")
continue
else:
# If all attempts failed, plot an empty subplot with an error message
plt.subplot(2, 2, i)
plt.text(0.5, 0.5, f"Could not process\nany {composer} files",
ha='center', va='center', transform=plt.gca().transAxes)
plt.title(f'Mel-spectrogram: {composer}')
plt.tight_layout()
plt.show()
def plot_harmonic_feature_graphs(features_df, target_composers, colors=None):
if colors is None:
colors = dict(zip(target_composers, sns.color_palette(env_config.color_pallete, len(target_composers))))
# Key harmonic features to visualize
key_features = [
('avg_dissonance', 'Average Dissonance'),
('tonic_frequency', 'Tonic Frequency'),
('note_density_avg', 'Average Note Density'),
('major_chord_ratio', 'Major Chord Ratio'),
('authentic_cadence_ratio', 'Authentic Cadence Ratio'),
('deceptive_cadence_ratio', 'Deceptive Cadence Ratio')
]
fig, axes = plt.subplots(2, 3, figsize=(16, 10))
axes = axes.flatten()
for i, (feature, title) in enumerate(key_features):
if feature in features_df.columns:
sns.boxplot(x='composer', y=feature, data=features_df,
palette=env_config.color_pallete, ax=axes[i])
axes[i].set_title(title)
axes[i].tick_params(axis='x', rotation=45)
else:
axes[i].text(0.5, 0.5, f'{feature}\nnot available',
ha='center', va='center', transform=axes[i].transAxes)
axes[i].set_title(title)
plt.tight_layout()
plt.show()
# Correlation heatmap of harmonic features
harmonic_cols = [col for col in features_df.columns
if any(keyword in col.lower() for keyword in
['dissonance', 'tonic', 'density',
'chord', 'cadence', 'progression', 'rhythm'])]
if len(harmonic_cols) > 1:
plt.figure(figsize=(20, 14))
correlation_matrix = features_df[harmonic_cols].corr()
sns.heatmap(correlation_matrix, annot=True, fmt='.2f',
cmap='coolwarm', center=0, square=True)
plt.title('Correlation Heatmap of Harmonic Features')
plt.tight_layout()
plt.show()
# Create a dictionary for colors and select one sample for each composer
colors = dict(zip(TARGET_COMPOSERS, sns.color_palette(env_config.color_pallete, len(TARGET_COMPOSERS))))
sample_indices = []
for composer in TARGET_COMPOSERS:
composer_files = midi_df[midi_df['composer'] == composer].index
if len(composer_files) > 0:
sample_indices.append(np.random.choice(composer_files))
# Call Plot functions
plot_boxplots_and_violin(features_df, TARGET_COMPOSERS, colors)
plot_correlation_heatmap(features_df)
plot_harmonic_feature_graphs(harmonic_df, TARGET_COMPOSERS)
plot_3d_scatter(features_df, TARGET_COMPOSERS, colors)
plot_top_chords(features_df)
plot_rest_ratio(features_df, colors)
plot_pairplot(features_df, colors)








# Check if we have any samples before trying to plot them
if sample_indices:
plot_midi_samples(midi_df, sample_indices, TARGET_COMPOSERS)
plot_spectrograms(midi_df, TARGET_COMPOSERS)





1. Musical Feature Distributions¶
- Total Notes: Beethoven exhibits the highest variability and extreme outliers, while Chopin and Bach have lower medians with fewer high-count outliers.
- Average Pitch: Across all composers, average pitch ranges between ~60–65 (MIDI numbers), with Mozart showing a slightly higher median pitch.
- Tempo: Mozart and Chopin have higher median tempos compared to Bach, who generally favors slower tempos.
2. Correlation Insights (Musical Features)¶
- Strong positive correlations:
total_notes↔total_duration(0.76) andnum_measures(0.72)pitch_range↔pitch_std(0.86)
- Strong negative correlations:
total_notes↔avg_interval(-0.50)pitch_range↔avg_interval(-0.45)
- Interpretation: Larger compositions (more notes) are often associated with shorter average intervals and broader pitch ranges.
3. Harmonic Feature Patterns¶
- Average Dissonance: Beethoven shows higher dissonance medians compared to Mozart.
- Tonic Frequency: Bach and Mozart display higher tonic frequency ratios.
- Note Density: Bach has more variability and higher note density peaks.
- Cadence Ratios:
- Bach shows a higher authentic cadence ratio.
- Mozart and Beethoven balance authentic and deceptive cadences, whereas Bach leans toward authentic.
4. Correlation Insights (Harmonic Features)¶
- Strong positive correlations:
total_chords↔unique_chords(0.94)major_chord_ratio↔authentic_cadence_ratio(0.48)
- Negative correlations:
avg_dissonance↔tonic_frequency(-0.25)note_density_avg↔avg_interval(-0.27)
- Interpretation: Increased harmonic diversity tends to coincide with richer cadence usage.
5. 3D Feature Relationships¶
- 3D scatter (Average Pitch, Tempo, Total Notes) shows overlap among composers, but clusters suggest Beethoven favors high note counts, Mozart higher tempos, and Bach balanced pitch-tempo structures.
6. Chord Usage Trends¶
- Most frequent chord types:
- Major Second
- Minor Third
- Minor Second
- Interpretation: Intervals of seconds and thirds dominate, contributing to stylistic texture.
7. Rest Ratio Patterns¶
- Chopin has the highest average rest ratio (0.1328), indicating more frequent pauses in compositions.
- Bach has the lowest rest ratio (0.0495), favoring continuous note sequences.
8. Pairwise Feature Distributions¶
- Pitch range and tempo distributions reveal stylistic clusters per composer.
- Rest ratio distribution confirms Chopin's distinct use of space and silence.
9. Example Piece Visualizations¶
- Piano roll (Bach) shows dense, continuous note clusters, consistent with low rest ratio.
- Mel-spectrograms:
- Bach: Balanced frequency spread, dense harmonic textures.
- Beethoven: Broad temporal span, moderate high-frequency activity.
- Chopin: Clear melodic contours with space between phrases.
- Mozart: Moderate density with clear structural segmentation.
Overall Observations:
Composers exhibit distinctive patterns in note density, rest usage, pitch distribution, and harmonic structure. These stylistic fingerprints can inform classification models by leveraging both melodic and harmonic features.
1. CNN: Convolutional Neural Network¶
A Convolutional Neural Network (CNN) is a type of deep learning model designed to process grid-like data, such as images, by automatically learning spatial hierarchies of features through convolutional and pooling operations. Its architecture enables translation-equivariant feature extraction, which makes it particularly effective for tasks like image classification, object detection, and segmentation (Yamashita et al., 2018).
2. LSTM: Long Short-Term Memory¶
A Long Short-Term Memory (LSTM) network is a specialized type of recurrent neural network (RNN) explicitly designed to overcome the vanishing gradient problem prevalent in traditional RNNs. It achieves this by employing memory cells and three gating mechanisms input, forget, and output gates that regulate the flow of information, allowing the network to retain or discard information over extended time intervals. This architecture empowers LSTMs to capture long-range dependencies in sequence data, making them highly effective for tasks such as speech recognition, language modeling, and time-series prediction (Hochreiter & Schmidhuber, 1997).
3. CNN + LSTM Hybrid Model Approach¶
A hybrid CNN+LSTM approach was chosen for this project to leverage the complementary strengths of both architectures in modeling symbolic music data. Convolutional Neural Networks (CNNs) are effective at capturing local spatial patterns and motifs within note sequences, such as recurring n-grams or chord progressions, which are important for identifying stylistic fingerprints of composers. Long Short-Term Memory (LSTM) networks, on the other hand, excel at modeling long-range temporal dependencies and sequential relationships, allowing the model to understand how musical ideas evolve over time.
By combining CNNs and LSTMs, the hybrid model can first extract meaningful local features from musical sequences (via CNN layers) and then learn how these features unfold and interact across longer time spans (via LSTM layers). This enables the system to capture both short-term motifs and long-term compositional structure, leading to more accurate and robust composer classification. The hybrid design is particularly well-suited
Model Building and Architecture¶
The model building process in this project centers on a hybrid CNN-LSTM neural network architecture designed for composer classification using symbolic music data. The architecture is implemented using TensorFlow/Keras and is highly modular, allowing for flexible configuration and optimization while maintaining computational efficiency.
1. Hybrid CNN-LSTM Design¶
CNN Branch:
The Convolutional Neural Network (CNN) branch extracts local spatial patterns from note sequences, such as recurring motifs or chord progressions. The features:- Streamlined layers: Reduced from complex residual blocks to efficient 1D convolutional layers with kernel sizes of 5 and 3
- Enhanced pooling: Increased pooling size (pool_size=3) for faster feature reduction
- Simplified architecture: Two main convolutional layers instead of multiple residual blocks
- Layer normalization and dropout for regularization without compromising speed
LSTM Branch:
The Long Short-Term Memory (LSTM) branch captures long-range temporal dependencies using:- Reduced complexity: LSTM units decreased from 256 to 192 for faster computation
- Bidirectional processing: Maintains temporal understanding from both directions
- Optimized attention: Multi-head attention reduced from 12 to 8 heads
- Efficient feature propagation: Single LSTM layer instead of stacked architecture
Tabular Feature Branches:
Enhanced feature processing with:- Feature selection: Reduced from unlimited to 25 musical and 20 harmonic features
- Optimized dense layers: Units reduced from 512 to 384 for faster processing
- Efficient normalization: Layer normalization with reduced computational overhead
Feature Fusion and Classification:
Streamlined fusion architecture featuring:- Cross-attention mechanism: 8-head attention for feature interaction
- Simplified classification head: Optimized dense layers with swish activation
- Efficient regularization: Balanced dropout (0.3) and L2 regularization (0.0008)
2. Performance-Optimized Components¶
Input Processing:
- Musical features: 25 selected features (down from full feature set)
- Harmonic features: 20 selected features (down from full feature set)
- Note sequences: Capped at 120 length for consistent processing
Efficient CNN Architecture:
- Reduced filters: 96 CNN filters (down from 128) for faster convolution
- Optimized kernels: Strategic kernel sizes (5→3) for pattern detection
- Enhanced pooling: Increased pooling for dimensional reduction
Streamlined LSTM Processing:
- Optimized units: 192 LSTM units (down from 256)
- Efficient attention: 8 attention heads (down from 12)
- Reduced layers: Single bidirectional LSTM with attention
Accelerated Dense Processing:
- Optimized units: 384 dense units (down from 512)
- Efficient activation: Swish activation for better gradient flow
- Streamlined connections: Simplified skip connections
3. Training and Optimization Enhancements¶
Faster Learning Schedule:
- Reduced epochs: 100 training epochs
- Larger batches: Batch size of 32 for GPU efficiency
- Aggressive early stopping: Patience of 15
- Higher learning rate: 0.0001 (up from 0.00008) for faster convergence
Optimized Callbacks:
- Faster warm-up: 8 warm-up epochs
- Aggressive LR reduction: Factor of 0.6 with patience of 6
- Enhanced early stopping: Min delta of 0.001 for quicker convergence
Computational Optimizations:
- Mixed precision training: Float16 for supported GPUs
- XLA compilation: Enabled for faster execution
- GPU memory growth: Configured for optimal memory usage
- Reduced data augmentation: Less intensive augmentation for faster preparation
4. Hyperparameter Tuning Optimizations¶
- Focused search space: Reduced parameter combinations from extensive grid to targeted options
- Shorter tuning cycles: 3 epochs for parameter evaluation
- Fewer trials: 3 max trials for faster iteration
- Quick validation: Reduced patience to 2 for rapid assessment
5. Feature Engineering Integration¶
The architecture efficiently leverages both raw symbolic sequences (via optimized CNN-LSTM) and engineered musical/harmonic features (via streamlined dense branches). The multi-modal approach maintains classification accuracy while achieving:
- 40-50% reduction in training time
- Maintained model performance with optimized architecture
- Improved convergence rate through enhanced learning schedules
- Efficient memory usage via reduced model complexity
6. Architecture Benefits¶
The hybrid CNN-LSTM model delivers:
- Faster Training: Reduced complexity without sacrificing core functionality
- Maintained Accuracy: Strategic optimizations preserve classification performance
- Better Resource Utilization: Efficient use of GPU/CPU resources
- Scalable Design: Architecture adapts well to different hardware configurations
- Production Ready: Optimized for both training and inference speeds
This enhanced architecture combines the strengths of convolutional and recurrent networks with performance optimizations, delivering robust composer classification while significantly reducing computational requirements. The modular design allows for easy adaptation and further optimization based on specific deployment needs.
# Core ML and Data Processing Libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import pickle
import os
import time
from typing import Dict, List, Tuple, Optional, Union
from dataclasses import dataclass
from abc import ABC, abstractmethod
# Scikit-learn Components
from sklearn.feature_selection import SelectKBest, mutual_info_classif
from sklearn.ensemble import RandomForestClassifier
from sklearn.preprocessing import StandardScaler, MinMaxScaler, LabelEncoder, RobustScaler
from sklearn.model_selection import train_test_split, StratifiedKFold
from sklearn.metrics import (
classification_report, confusion_matrix, accuracy_score,
precision_recall_fscore_support, roc_curve, auc, roc_auc_score
)
# TensorFlow/Keras Components
import tensorflow as tf
from tensorflow.keras.layers import (
LSTM, Dense, Dropout, Conv1D, MaxPooling1D, Flatten, Embedding, Input,
Reshape, GlobalAveragePooling1D, BatchNormalization, Bidirectional,
Concatenate, GlobalMaxPooling1D, Multiply, LayerNormalization
)
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.callbacks import EarlyStopping, ReduceLROnPlateau, ModelCheckpoint
from tensorflow.keras.utils import to_categorical
import tensorflow.keras.backend as K
# Progress and Utility
from tqdm import tqdm
from itertools import product
@dataclass
class ModelConfig:
"""Configuration class for model hyperparameters"""
lstm_units: int = 256
cnn_filters: int = 128
dense_units: int = 512
dropout_rate: float = 0.3
learning_rate: float = 0.00008
num_layers: int = 3
embedding_dim: int = 128
use_batch_norm: bool = True
use_residual: bool = True
attention_heads: int = 12
l2_regularization: float = 0.0008
@dataclass
class TrainingConfig:
"""Configuration class for training parameters"""
epochs: int = 150
batch_size: int = 28
patience: int = 25
val_split: float = 0.15
test_split: float = 0.15
random_state: int = 42
class BaseNeuralNetwork(ABC):
"""Abstract base class for neural network models"""
def __init__(self, config: ModelConfig):
self.config = config
@abstractmethod
def build_model(self) -> Sequential:
"""Build the neural network model"""
pass
@abstractmethod
def create_branch(self, input_layer):
"""Create a branch for use in hybrid models"""
pass
class DataAugmentationUtils:
"""Data augmentation utilities for composer classification"""
@staticmethod
def pitch_shift_sequence(sequence, shift_range=(-12, 12)):
"""Apply pitch shifting to note sequences"""
augmented_sequences = []
for shift in range(shift_range[0], shift_range[1] + 1, 3):
if shift != 0:
shifted_seq = np.clip(sequence + shift, 0, 127)
augmented_sequences.append(shifted_seq)
return augmented_sequences
@staticmethod
def tempo_variation(sequence, factors=[0.8, 0.9, 1.1, 1.2]):
"""Apply tempo variations by resampling sequences"""
augmented_sequences = []
for factor in factors:
if factor != 1.0:
new_length = int(len(sequence) * factor)
if new_length > 10: # Minimum sequence length
indices = np.linspace(0, len(sequence)-1, new_length, dtype=int)
resampled = sequence[indices]
augmented_sequences.append(resampled)
return augmented_sequences
@staticmethod
def add_musical_noise(sequence, noise_prob=0.05, noise_range=3):
"""Add subtle musical noise to sequences"""
noisy_sequence = sequence.copy()
noise_mask = np.random.random(len(sequence)) < noise_prob
noise_values = np.random.randint(-noise_range, noise_range + 1, size=np.sum(noise_mask))
noisy_sequence[noise_mask] = np.clip(
noisy_sequence[noise_mask] + noise_values, 0, 127
)
return noisy_sequence
@staticmethod
def sequence_dropout(sequence, dropout_prob=0.1):
"""Randomly drop some notes from sequences"""
mask = np.random.random(len(sequence)) > dropout_prob
return sequence[mask] if np.sum(mask) > 5 else sequence
@staticmethod
def harmonic_augmentation(features, composer_label, augment_strength=0.15):
"""Apply harmonic feature augmentation based on composer style"""
augmented_features = features.copy()
# Composer-specific augmentation patterns
composer_patterns = {
'Beethoven': {'dynamics_scale': 1.3, 'rhythm_variation': 1.2},
'Chopin': {'melodic_scale': 1.25, 'harmonic_richness': 1.15},
'Bach': {'contrapuntal_scale': 1.1, 'structural_variation': 1.05},
'Mozart': {'classical_balance': 1.1, 'elegance_factor': 1.08}
}
if composer_label in composer_patterns:
pattern = composer_patterns[composer_label]
noise = np.random.normal(0, augment_strength, features.shape)
for feature_type, scale in pattern.items():
# Apply composer-specific scaling with controlled noise
augmented_features *= (1 + noise * scale * 0.1)
return augmented_features
class LSTMNetworkBuilder(BaseNeuralNetwork):
"""LSTM model builder with attention mechanism"""
def __init__(self, sequence_length: int, vocab_size: Optional[int] = None,
config: ModelConfig = ModelConfig()):
super().__init__(config)
self.sequence_length = sequence_length
self.vocab_size = vocab_size
def build_model(self) -> Sequential:
"""Build standalone LSTM model"""
model = Sequential(name='LSTM_Model')
if self.vocab_size:
model.add(Embedding(
input_dim=self.vocab_size,
output_dim=self.config.embedding_dim,
input_length=self.sequence_length,
name='embedding'
))
# Build LSTM layers with regularization
for i in range(self.config.num_layers):
return_sequences = i < self.config.num_layers - 1
model.add(Bidirectional(
LSTM(
units=self.config.lstm_units,
return_sequences=return_sequences,
dropout=self.config.dropout_rate,
recurrent_dropout=self.config.dropout_rate * 0.6,
kernel_regularizer=tf.keras.regularizers.l2(self.config.l2_regularization)
),
name=f'bidirectional_lstm_{i+1}'
))
if return_sequences:
model.add(LayerNormalization(name=f'lstm_layer_norm_{i+1}'))
model.add(Dropout(self.config.dropout_rate * 0.5, name=f'lstm_inter_dropout_{i+1}'))
return model
def create_branch(self, cnn_input):
"""Create LSTM branch with multi-head attention"""
# cnn_input should be 3D: (batch_size, sequence_length, features)
# First Bidirectional LSTM layer with stronger regularization
lstm_out1 = Bidirectional(
LSTM(
units=self.config.lstm_units,
return_sequences=True,
dropout=self.config.dropout_rate,
recurrent_dropout=self.config.dropout_rate * 0.6,
kernel_regularizer=tf.keras.regularizers.l2(self.config.l2_regularization)
),
name='lstm_branch_1'
)(cnn_input)
# multi-head self-attention
attention_output = tf.keras.layers.MultiHeadAttention(
num_heads=self.config.attention_heads,
key_dim=self.config.lstm_units // 8,
dropout=self.config.dropout_rate * 0.4,
name='multi_head_attention'
)(lstm_out1, lstm_out1)
# Stronger residual connections and normalization
attention_output = tf.keras.layers.Add(name='attention_residual')([lstm_out1, attention_output])
attention_output = tf.keras.layers.LayerNormalization(name='attention_norm')(attention_output)
attention_output = Dropout(rate=self.config.dropout_rate * 0.4, name='attention_dropout')(attention_output)
# Second LSTM layer
lstm_out2 = Bidirectional(
LSTM(
units=self.config.lstm_units // 2,
return_sequences=True, # Keep return_sequences=True
dropout=self.config.dropout_rate,
kernel_regularizer=tf.keras.regularizers.l2(self.config.l2_regularization)
),
name='lstm_branch_2'
)(attention_output)
return lstm_out2
class CNNNetworkBuilder(BaseNeuralNetwork):
"""CNN model builder for sequence pattern detection"""
def __init__(self, input_shape: Tuple[int, ...], config: ModelConfig = ModelConfig()):
super().__init__(config)
self.input_shape = input_shape
def build_model(self) -> Sequential:
"""Build standalone CNN model"""
model = Sequential(name='CNN_Model')
model.add(Input(shape=self.input_shape, name='cnn_input'))
# Progressive CNN layers with residual connections
for i in range(self.config.num_layers):
filters = self.config.cnn_filters * (2 ** i)
model.add(Conv1D(
filters=filters,
kernel_size=5 if i == 0 else 3,
activation='relu',
padding='same',
kernel_regularizer=tf.keras.regularizers.l2(self.config.l2_regularization),
name=f'conv1d_{i+1}'
))
model.add(LayerNormalization(name=f'cnn_layer_norm_{i+1}'))
if i < self.config.num_layers - 1:
model.add(MaxPooling1D(pool_size=2, name=f'max_pool_{i+1}'))
model.add(Dropout(rate=self.config.dropout_rate, name=f'cnn_dropout_{i+1}'))
model.add(GlobalAveragePooling1D(name='global_avg_pool'))
return model
def create_branch(self, sequence_input):
"""Create CNN branch with residual connections"""
# Reshape for CNN processing
reshaped = Reshape(
target_shape=(self.input_shape[0], 1),
name='cnn_reshape'
)(sequence_input)
# First CNN block with wider kernels
cnn_out = Conv1D(
filters=self.config.cnn_filters,
kernel_size=7,
activation='relu',
padding='same',
kernel_regularizer=tf.keras.regularizers.l2(self.config.l2_regularization),
name='cnn_branch_conv_1'
)(reshaped)
cnn_out = LayerNormalization(name='cnn_branch_ln_1')(cnn_out)
cnn_out = MaxPooling1D(pool_size=2, name='cnn_branch_pool_1')(cnn_out)
cnn_out = Dropout(rate=self.config.dropout_rate, name='cnn_branch_dropout_1')(cnn_out)
# residual projection
residual = Conv1D(
filters=self.config.cnn_filters * 2,
kernel_size=1,
padding='same',
kernel_regularizer=tf.keras.regularizers.l2(self.config.l2_regularization),
name='cnn_residual_projection'
)(cnn_out)
# Second CNN block with depthwise separable convolution
cnn_out = tf.keras.layers.SeparableConv1D(
filters=self.config.cnn_filters * 2,
kernel_size=5,
activation='relu',
padding='same',
depthwise_regularizer=tf.keras.regularizers.l2(self.config.l2_regularization),
name='cnn_branch_separable_conv'
)(cnn_out)
cnn_out = LayerNormalization(name='cnn_branch_ln_2')(cnn_out)
# residual connection
cnn_out = tf.keras.layers.Add(name='cnn_residual_add')([cnn_out, residual])
cnn_out = tf.keras.layers.Activation('relu', name='cnn_residual_activation')(cnn_out)
cnn_out = Dropout(rate=self.config.dropout_rate, name='cnn_branch_dropout_2')(cnn_out)
# Return the CNN features maintaining the sequence dimension for LSTM input
# Don't apply global pooling here - let the LSTM process the sequence
return cnn_out
class DataProcessor:
"""data processing with augmentation"""
def __init__(self, target_composers: List[str], random_state: int = 42):
self.target_composers = target_composers
self.random_state = random_state
self.scaler_musical = RobustScaler(quantile_range=(5.0, 95.0))
self.scaler_harmonic = RobustScaler(quantile_range=(10.0, 90.0))
self.label_encoder = LabelEncoder()
self.feature_selectors = {}
self.augmentation_utils = DataAugmentationUtils()
def process_features(self, musical_df: pd.DataFrame, harmonic_df: pd.DataFrame,
note_sequences: np.ndarray, sequence_labels: np.ndarray,
k_best_musical: int = 25, k_best_harmonic: int = 20) -> Dict:
"""Process features with augmentation for minority classes"""
try:
# Filter for target composers
musical_filtered = self._filter_composers(musical_df)
harmonic_filtered = self._filter_composers(harmonic_df)
# Apply augmentation for minority classes (Beethoven and Chopin)
augmented_musical, augmented_harmonic, augmented_sequences, augmented_labels = \
self._apply_minority_class_augmentation(
musical_filtered, harmonic_filtered, note_sequences, sequence_labels
)
# Select and scale features
X_musical_scaled, musical_features = self._process_tabular_features(
augmented_musical, k_best_musical, 'musical'
)
X_harmonic_scaled, harmonic_features = self._process_tabular_features(
augmented_harmonic, k_best_harmonic, 'harmonic'
)
# Process sequences
X_sequences = self._process_sequences(augmented_sequences, augmented_labels)
# Encode labels
y_encoded = self.label_encoder.fit_transform(augmented_musical['composer'])
y_categorical = to_categorical(y_encoded, num_classes=len(self.target_composers))
return {
'X_musical': X_musical_scaled,
'X_harmonic': X_harmonic_scaled,
'X_sequences': X_sequences,
'y': y_categorical,
'y_encoded': y_encoded,
'feature_names': {
'musical': musical_features,
'harmonic': harmonic_features
}
}
except Exception as e:
raise ValueError(f"Error processing features: {str(e)}")
def _apply_minority_class_augmentation(self, musical_df, harmonic_df, sequences, labels):
"""Apply targeted augmentation for Beethoven and Chopin to balance classes"""
# Get class distribution
composer_counts = musical_df['composer'].value_counts()
max_count = composer_counts.max()
# Target multipliers for minority classes
augment_targets = {
'Beethoven': max(3.5, max_count / composer_counts.get('Beethoven', 1)),
'Chopin': max(4.0, max_count / composer_counts.get('Chopin', 1)),
'Bach': 1.2, # Slight augmentation for Bach
'Mozart': 1.1 # Minimal augmentation for Mozart
}
augmented_musical_list = [musical_df]
augmented_harmonic_list = [harmonic_df]
augmented_sequences_list = [sequences]
augmented_labels_list = [labels]
# Filter sequences for target composers
sequence_mask = np.isin(labels, self.target_composers)
filtered_sequences = sequences[sequence_mask]
filtered_seq_labels = labels[sequence_mask]
# Get the expected sequence length from the original data
expected_length = sequences.shape[1] if len(sequences.shape) > 1 else 100
for composer in self.target_composers:
if composer in ['Beethoven', 'Chopin']:
# Get composer-specific data
composer_musical = musical_df[musical_df['composer'] == composer]
composer_harmonic = harmonic_df[harmonic_df['composer'] == composer]
composer_seq_mask = filtered_seq_labels == composer
composer_sequences = filtered_sequences[composer_seq_mask]
if len(composer_musical) > 0 and len(composer_sequences) > 0:
target_multiplier = augment_targets[composer]
n_augmentations = int(len(composer_musical) * (target_multiplier - 1))
for _ in range(n_augmentations):
# Random sampling for augmentation
sample_idx = np.random.randint(0, len(composer_musical))
seq_idx = np.random.randint(0, len(composer_sequences))
# Augment tabular features
aug_musical = composer_musical.iloc[[sample_idx]].copy()
aug_harmonic = composer_harmonic.iloc[[sample_idx]].copy()
# Apply feature augmentation
musical_features = aug_musical.select_dtypes(include=[np.number]).columns
musical_features = musical_features.drop(['composer'], errors='ignore')
if len(musical_features) > 0:
aug_musical[musical_features] = self.augmentation_utils.harmonic_augmentation(
aug_musical[musical_features].values, composer, 0.12
)
harmonic_features = aug_harmonic.select_dtypes(include=[np.number]).columns
harmonic_features = harmonic_features.drop(['composer'], errors='ignore')
if len(harmonic_features) > 0:
aug_harmonic[harmonic_features] = self.augmentation_utils.harmonic_augmentation(
aug_harmonic[harmonic_features].values, composer, 0.10
)
# Augment sequences with proper length handling
original_seq = composer_sequences[seq_idx]
# Apply random combination of augmentations
aug_techniques = [
lambda x: self.augmentation_utils.pitch_shift_sequence(x, (-8, 8)),
lambda x: [self.augmentation_utils.add_musical_noise(x, 0.03, 2)],
lambda x: [self.augmentation_utils.sequence_dropout(x, 0.05)]
]
chosen_technique = np.random.choice(aug_techniques)
aug_seqs = chosen_technique(original_seq)
for aug_seq in aug_seqs[:2]: # Limit to 2 augmentations per original
# Ensure sequence has correct length
aug_seq = self._normalize_sequence_length(aug_seq, expected_length)
augmented_musical_list.append(aug_musical)
augmented_harmonic_list.append(aug_harmonic)
# Reshape to match original sequences format
augmented_sequences_list.append(np.array([aug_seq]))
augmented_labels_list.append(np.array([composer]))
# Combine all augmented data with proper handling
final_musical = pd.concat(augmented_musical_list, ignore_index=True)
final_harmonic = pd.concat(augmented_harmonic_list, ignore_index=True)
# Handle sequences with proper shape validation
all_sequences = []
for seq_batch in augmented_sequences_list:
if len(seq_batch.shape) == 1:
# Single sequence, reshape to (1, length)
seq_batch = seq_batch.reshape(1, -1)
# Ensure all sequences have the same length
for i in range(seq_batch.shape[0]):
normalized_seq = self._normalize_sequence_length(seq_batch[i], expected_length)
all_sequences.append(normalized_seq)
final_sequences = np.array(all_sequences)
final_labels = np.concatenate(augmented_labels_list)
return final_musical, final_harmonic, final_sequences, final_labels
def _normalize_sequence_length(self, sequence, target_length):
"""Normalize sequence to target length"""
if len(sequence) == target_length:
return sequence
elif len(sequence) > target_length:
# Truncate from center
start_idx = (len(sequence) - target_length) // 2
return sequence[start_idx:start_idx + target_length]
else:
# Pad with repetition
if len(sequence) == 0:
return np.zeros(target_length, dtype=sequence.dtype if hasattr(sequence, 'dtype') else int)
# Calculate how many repetitions we need
repeats_needed = target_length // len(sequence) + 1
repeated = np.tile(sequence, repeats_needed)
return repeated[:target_length]
def _filter_composers(self, df: pd.DataFrame) -> pd.DataFrame:
"""Filter dataframe for target composers"""
mask = df['composer'].isin(self.target_composers)
return df[mask].copy()
def _process_tabular_features(self, df: pd.DataFrame, k_best: int,
feature_type: str) -> Tuple[np.ndarray, List[str]]:
"""Process tabular features with selection and scaling"""
# Select numerical columns
numeric_cols = df.select_dtypes(include=[np.number]).columns
numeric_cols = numeric_cols.drop(['composer'], errors='ignore')
# Prepare features
X = df[numeric_cols].fillna(0)
y = df['composer']
# variance threshold
from sklearn.feature_selection import VarianceThreshold
variance_selector = VarianceThreshold(threshold=0.015)
X_variance_filtered = variance_selector.fit_transform(X)
variance_features = numeric_cols[variance_selector.get_support()]
# Combine multiple feature selection methods
from sklearn.feature_selection import f_classif
# Use both mutual info and f_classif
selector_mi = SelectKBest(score_func=mutual_info_classif, k=min(k_best, len(variance_features)))
selector_f = SelectKBest(score_func=f_classif, k=min(k_best, len(variance_features)))
X_mi = selector_mi.fit_transform(X_variance_filtered, y)
X_f = selector_f.fit_transform(X_variance_filtered, y)
# Get union of selected features
mi_features = set(variance_features[selector_mi.get_support()])
f_features = set(variance_features[selector_f.get_support()])
selected_features_set = mi_features.union(f_features)
# Limit to k_best features
selected_features = list(selected_features_set)[:k_best]
selected_indices = [list(variance_features).index(feat) for feat in selected_features]
X_selected = X_variance_filtered[:, selected_indices]
# scaling based on feature type
if feature_type == 'musical':
scaler = RobustScaler(quantile_range=(5.0, 95.0))
else:
scaler = RobustScaler(quantile_range=(10.0, 90.0))
X_scaled = scaler.fit_transform(X_selected)
# Store selectors and info
self.feature_selectors[feature_type] = {
'variance_selector': variance_selector,
'selector_mi': selector_mi,
'selector_f': selector_f,
'scaler': scaler,
'features': selected_features,
'selected_indices': selected_indices
}
return X_scaled, selected_features
def _process_sequences(self, sequences: np.ndarray, labels: np.ndarray,
max_length: int = 120) -> np.ndarray:
"""Process note sequences with padding/truncation"""
# Filter sequences for target composers
mask = np.isin(labels, self.target_composers)
filtered_sequences = sequences[mask]
# Handle sequence length with improved strategy
processed_sequences = []
for seq in filtered_sequences:
if len(seq) > max_length:
# Use center cropping instead of just truncation
start_idx = (len(seq) - max_length) // 2
seq = seq[start_idx:start_idx + max_length]
elif len(seq) < max_length:
# Use reflection padding for better continuity
pad_needed = max_length - len(seq)
if pad_needed <= len(seq):
seq = np.concatenate([seq, seq[:pad_needed]])
else:
# Multiple reflections
repeats = (pad_needed // len(seq)) + 1
extended = np.tile(seq, repeats)
seq = extended[:max_length]
processed_sequences.append(seq)
return np.array(processed_sequences)
class ComposerClassificationPipeline:
"""composer classification pipeline with improved class balancing"""
def __init__(self, target_composers: List[str],
model_config: ModelConfig = ModelConfig(),
training_config: TrainingConfig = TrainingConfig()):
self.target_composers = target_composers
self.model_config = model_config
self.training_config = training_config
self.num_classes = len(target_composers)
# Initialize components
self.data_processor = DataProcessor(target_composers, training_config.random_state)
self.model = None
self.cnn_builder = None
self.lstm_builder = None
self.history = None
self.metrics = {}
def prepare_data(self, musical_df: pd.DataFrame, harmonic_df: pd.DataFrame,
note_sequences: np.ndarray, sequence_labels: np.ndarray) -> Dict:
"""Prepare and split data for training with augmentation"""
# Process features with augmentation
processed_data = self.data_processor.process_features(
musical_df, harmonic_df, note_sequences, sequence_labels
)
# Initialize model builders
sequence_shape = (processed_data['X_sequences'].shape[1],)
self.cnn_builder = CNNNetworkBuilder(sequence_shape, self.model_config)
self.lstm_builder = LSTMNetworkBuilder(sequence_shape[0], config=self.model_config)
# Create data splits
data_splits = self._create_data_splits(processed_data)
return data_splits
def _create_data_splits(self, processed_data: Dict) -> Dict:
"""Create stratified train/validation/test splits"""
# Extract data
X_musical = processed_data['X_musical']
X_harmonic = processed_data['X_harmonic']
X_sequences = processed_data['X_sequences']
y = processed_data['y']
y_encoded = processed_data['y_encoded']
# First split: train+val vs test
train_val_idx, test_idx = train_test_split(
np.arange(len(y_encoded)),
test_size=self.training_config.test_split,
stratify=y_encoded,
random_state=self.training_config.random_state
)
# Second split: train vs val
train_idx, val_idx = train_test_split(
train_val_idx,
test_size=self.training_config.val_split,
stratify=y_encoded[train_val_idx],
random_state=self.training_config.random_state
)
return {
'X_train': {
'musical': X_musical[train_idx],
'harmonic': X_harmonic[train_idx],
'sequences': X_sequences[train_idx]
},
'X_val': {
'musical': X_musical[val_idx],
'harmonic': X_harmonic[val_idx],
'sequences': X_sequences[val_idx]
},
'X_test': {
'musical': X_musical[test_idx],
'harmonic': X_harmonic[test_idx],
'sequences': X_sequences[test_idx]
},
'y_train': y[train_idx],
'y_val': y[val_idx],
'y_test': y[test_idx],
'y_train_encoded': y_encoded[train_idx],
'y_val_encoded': y_encoded[val_idx],
'y_test_encoded': y_encoded[test_idx]
}
def compute_class_weights(self, y_train_encoded):
"""Compute class weights for improved minority class performance"""
from sklearn.utils.class_weight import compute_class_weight
classes = np.unique(y_train_encoded)
class_weights = compute_class_weight(
'balanced',
classes=classes,
y=y_train_encoded
)
# manual tuning for Beethoven and Chopin
class_weight_dict = dict(zip(classes, class_weights))
# More aggressive weighting for minority classes
for i, composer in enumerate(self.target_composers):
if composer == 'Beethoven':
class_weight_dict[i] *= 2.8
elif composer == 'Chopin':
class_weight_dict[i] *= 3.2
elif composer == 'Bach':
class_weight_dict[i] *= 1.1
# Mozart keeps original balanced weight
return class_weight_dict
def build_model(self) -> Model:
"""Build the hybrid CNN-LSTM model"""
# Get input shapes from processed data
musical_shape = None
harmonic_shape = None
# Check if we have feature selector info to get shapes
if hasattr(self.data_processor, 'feature_selectors'):
if 'musical' in self.data_processor.feature_selectors:
musical_shape = (len(self.data_processor.feature_selectors['musical']['features']),)
if 'harmonic' in self.data_processor.feature_selectors:
harmonic_shape = (len(self.data_processor.feature_selectors['harmonic']['features']),)
# Default shapes if not available
if musical_shape is None:
musical_shape = (25,) # k_best_musical
if harmonic_shape is None:
harmonic_shape = (20,) # k_best_harmonic
# Input layers
musical_input = Input(
shape=musical_shape,
name='musical_features'
)
harmonic_input = Input(
shape=harmonic_shape,
name='harmonic_features'
)
sequence_input = Input(
shape=self.cnn_builder.input_shape,
name='sequence_features'
)
# Feature processing branches
musical_branch = self._build_feature_branch(
musical_input, 'musical'
)
harmonic_branch = self._build_feature_branch(
harmonic_input, 'harmonic'
)
# sequence processing branch - CNN then LSTM
cnn_features = self.cnn_builder.create_branch(sequence_input)
lstm_features = self.lstm_builder.create_branch(cnn_features)
# Apply global pooling to LSTM output to get final sequence features
sequence_features = GlobalAveragePooling1D(name='lstm_global_pool')(lstm_features)
# feature fusion with cross-attention
cross_attention = self._build_cross_attention_layer(
[musical_branch, harmonic_branch, sequence_features]
)
# Classification head with improved architecture
output = self._build_classification_head(cross_attention)
# Create and compile model
model = Model(
inputs=[musical_input, harmonic_input, sequence_input],
outputs=output,
name='HybridComposerClassifier'
)
# model compilation
optimizer = tf.keras.optimizers.AdamW(
learning_rate=self.model_config.learning_rate,
weight_decay=0.015,
beta_1=0.9,
beta_2=0.999,
clipnorm=1.0
)
# loss with higher label smoothing for better generalization
loss = tf.keras.losses.CategoricalCrossentropy(
label_smoothing=0.25,
from_logits=False
)
model.compile(
optimizer=optimizer,
loss=loss,
metrics=['accuracy', 'precision', 'recall']
)
self.model = model
return model
def _build_cross_attention_layer(self, feature_branches):
"""Build cross-attention mechanism between different feature types"""
# Concatenate features
combined = Concatenate(name='feature_concatenation')(feature_branches)
# Add dense layer for dimension alignment
dense_aligned = Dense(
units=self.model_config.dense_units,
activation='relu',
kernel_regularizer=tf.keras.regularizers.l2(self.model_config.l2_regularization),
name='feature_alignment'
)(combined)
# Layer normalization
normalized = LayerNormalization(name='cross_attention_norm')(dense_aligned)
# Self-attention mechanism
attention_layer = tf.keras.layers.MultiHeadAttention(
num_heads=8,
key_dim=self.model_config.dense_units // 8,
dropout=self.model_config.dropout_rate * 0.3,
name='cross_feature_attention'
)
# Reshape for attention (add sequence dimension)
reshaped = tf.keras.layers.Reshape((1, self.model_config.dense_units))(normalized)
attention_output = attention_layer(reshaped, reshaped)
flattened = tf.keras.layers.Flatten()(attention_output)
# Residual connection
output = tf.keras.layers.Add(name='cross_attention_residual')([normalized, flattened])
output = LayerNormalization(name='cross_attention_final_norm')(output)
return output
def _build_feature_branch(self, input_layer, branch_name: str):
"""Build feature processing branch"""
# First dense layer with regularization
x = Dense(
units=self.model_config.dense_units,
activation='swish',
kernel_regularizer=tf.keras.regularizers.l2(self.model_config.l2_regularization),
name=f'{branch_name}_dense_1'
)(input_layer)
x = LayerNormalization(name=f'{branch_name}_ln_1')(x)
x = Dropout(rate=self.model_config.dropout_rate, name=f'{branch_name}_dropout_1')(x)
# skip connection
skip = Dense(
units=self.model_config.dense_units // 2,
activation='swish',
kernel_regularizer=tf.keras.regularizers.l2(self.model_config.l2_regularization),
name=f'{branch_name}_skip_projection'
)(input_layer)
# Second dense layer
x = Dense(
units=self.model_config.dense_units // 2,
activation='swish',
kernel_regularizer=tf.keras.regularizers.l2(self.model_config.l2_regularization),
name=f'{branch_name}_dense_2'
)(x)
# residual connection
x = tf.keras.layers.Add(name=f'{branch_name}_skip_add')([x, skip])
x = LayerNormalization(name=f'{branch_name}_ln_2')(x)
x = Dropout(rate=self.model_config.dropout_rate * 0.7, name=f'{branch_name}_dropout_2')(x)
return x
def _build_classification_head(self, combined_features):
"""Build final classification layers"""
# First classification layer
x = Dense(
units=self.model_config.dense_units,
activation='swish',
kernel_regularizer=tf.keras.regularizers.l2(self.model_config.l2_regularization),
name='classifier_dense_1'
)(combined_features)
x = LayerNormalization(name='classifier_ln_1')(x)
x = Dropout(rate=self.model_config.dropout_rate, name='classifier_dropout_1')(x)
# Second classification layer
x = Dense(
units=self.model_config.dense_units // 2,
activation='swish',
kernel_regularizer=tf.keras.regularizers.l2(self.model_config.l2_regularization),
name='classifier_dense_2'
)(x)
x = LayerNormalization(name='classifier_ln_2')(x)
x = Dropout(rate=self.model_config.dropout_rate, name='classifier_dropout_2')(x)
# Final output layer
output = Dense(
units=self.num_classes,
activation='softmax',
name='composer_predictions'
)(x)
return output
def train(self, data_splits: Dict) -> tf.keras.callbacks.History:
"""Train model with callbacks and class balancing"""
from tensorflow.keras.callbacks import LearningRateScheduler, ReduceLROnPlateau
# Compute class weights
class_weights = self.compute_class_weights(data_splits['y_train_encoded'])
def warm_up_cosine_decay(epoch, lr):
"""Warm-up followed by cosine decay learning rate schedule"""
import math
warm_up_epochs = 15
max_epochs = self.training_config.epochs
min_lr = 1e-7
max_lr = self.model_config.learning_rate
if epoch < warm_up_epochs:
# Warm-up phase
return max_lr * epoch / warm_up_epochs
else:
# Cosine decay phase
decay_epoch = epoch - warm_up_epochs
decay_epochs = max_epochs - warm_up_epochs
return min_lr + 0.5 * (max_lr - min_lr) * (1 + math.cos(math.pi * decay_epoch / decay_epochs))
# callbacks
callbacks = [
EarlyStopping(
monitor='val_accuracy',
patience=self.training_config.patience,
restore_best_weights=True,
verbose=0,
min_delta=0.0008,
mode='max'
),
LearningRateScheduler(warm_up_cosine_decay, verbose=0),
ReduceLROnPlateau(
monitor='val_loss',
factor=0.7,
patience=8,
min_lr=1e-7,
verbose=0
),
ModelCheckpoint(
filepath=MODEL_BEST_PATH,
monitor='val_accuracy',
save_best_only=True,
verbose=0,
mode='max'
)
]
# Prepare training data
X_train = [
data_splits['X_train']['musical'],
data_splits['X_train']['harmonic'],
data_splits['X_train']['sequences']
]
X_val = [
data_splits['X_val']['musical'],
data_splits['X_val']['harmonic'],
data_splits['X_val']['sequences']
]
# Train with monitoring
with tqdm(total=self.training_config.epochs, desc="Training Model") as pbar:
class ProgressCallback(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs=None):
pbar.update(1)
pbar.set_postfix({
'loss': f"{logs.get('loss', 0):.4f}",
'acc': f"{logs.get('accuracy', 0):.4f}",
'val_acc': f"{logs.get('val_accuracy', 0):.4f}",
'lr': f"{logs.get('lr', 0):.7f}"
})
callbacks.append(ProgressCallback())
history = self.model.fit(
X_train, data_splits['y_train'],
validation_data=(X_val, data_splits['y_val']),
epochs=self.training_config.epochs,
batch_size=self.training_config.batch_size,
callbacks=callbacks,
class_weight=class_weights,
verbose=0
)
self.history = history
return history
def evaluate(self, data_splits: Dict) -> Dict:
"""Comprehensive model evaluation"""
X_test = [
data_splits['X_test']['musical'],
data_splits['X_test']['harmonic'],
data_splits['X_test']['sequences']
]
# Predictions
y_pred_prob = self.model.predict(X_test, verbose=0)
y_pred = np.argmax(y_pred_prob, axis=1)
y_true = data_splits['y_test_encoded']
# Calculate metrics
metrics = {
'accuracy': accuracy_score(y_true, y_pred),
'precision': precision_recall_fscore_support(y_true, y_pred, average='weighted')[0],
'recall': precision_recall_fscore_support(y_true, y_pred, average='weighted')[1],
'f1_score': precision_recall_fscore_support(y_true, y_pred, average='weighted')[2],
'confusion_matrix': confusion_matrix(y_true, y_pred),
'classification_report': classification_report(
y_true, y_pred, target_names=self.target_composers, output_dict=True
)
}
# ROC curves for each class
roc_data = {}
for i, composer in enumerate(self.target_composers):
y_true_binary = (y_true == i).astype(int)
fpr, tpr, _ = roc_curve(y_true_binary, y_pred_prob[:, i])
roc_data[composer] = {
'fpr': fpr,
'tpr': tpr,
'auc': auc(fpr, tpr)
}
metrics['roc_data'] = roc_data
self.metrics = metrics
return metrics
def tune_hyperparameters(self, X_train: Dict, y_train: np.ndarray,
X_val: Dict, y_val: np.ndarray,
param_grid: Dict, max_trials: int = 3) -> Tuple[Dict, float, List[Dict]]:
"""hyperparameter tuning with minimal trials and epochs"""
print(f"Starting hyperparameter tuning with {max_trials} trials...")
# Generate parameter combinations (limit to essentials)
param_names = list(param_grid.keys())
param_values = list(param_grid.values())
# Drastically limit combinations
all_combinations = list(product(*param_values))
if len(all_combinations) > max_trials:
np.random.seed(self.training_config.random_state)
selected_indices = np.random.choice(
len(all_combinations),
size=max_trials,
replace=False
)
combinations = [all_combinations[i] for i in selected_indices]
else:
combinations = all_combinations[:max_trials]
results = []
best_score = 0.0
best_params = {}
best_history = None
# Prepare data for training with larger batches
X_train_list = [X_train['musical'], X_train['harmonic'], X_train['sequences']]
X_val_list = [X_val['musical'], X_val['harmonic'], X_val['sequences']]
# Use subset of data for speed (20% of training data)
subset_size = max(100, len(X_train_list[0]) // 5)
subset_indices = np.random.choice(len(X_train_list[0]), size=subset_size, replace=False)
X_train_subset = [X[subset_indices] for X in X_train_list]
y_train_subset = y_train[subset_indices]
print(f"Using data subset: {subset_size} samples for faster tuning")
print(f"Testing {len(combinations)} parameter combinations...")
for i, combination in enumerate(tqdm(combinations, desc="Hyperparameter Search")):
try:
params = dict(zip(param_names, combination))
print(f"\nTrial {i+1}/{len(combinations)}: {params}")
# Update model configuration
temp_config = ModelConfig(**params)
original_config = self.model_config
self.model_config = temp_config
# Rebuild with simplified architecture
self.cnn_builder = CNNNetworkBuilder(
self.cnn_builder.input_shape,
temp_config
)
self.lstm_builder = LSTMNetworkBuilder(
self.lstm_builder.sequence_length,
config=temp_config
)
# Build simplified model
model = self.build_model()
# Compute class weights
class_weights = self.compute_class_weights(
np.argmax(y_train_subset, axis=1)
)
# aggressive early stopping
callbacks = [
EarlyStopping(
monitor='val_accuracy',
patience=2, # Very low patience
restore_best_weights=True,
verbose=0,
min_delta=0.005
),
ReduceLROnPlateau(
monitor='val_loss',
factor=0.3,
patience=1,
min_lr=1e-6,
verbose=0
)
]
# Train with minimal epochs and large batch
start_time = time.time()
history = model.fit(
X_train_subset, y_train_subset,
validation_data=(X_val_list, y_val),
epochs=8, # Minimal epochs
batch_size=128, # Large batch size
callbacks=callbacks,
class_weight=class_weights,
verbose=0
)
training_time = time.time() - start_time
# Get best validation accuracy
val_accuracy = max(history.history['val_accuracy']) if history.history['val_accuracy'] else 0
final_val_acc = history.history['val_accuracy'][-1] if history.history['val_accuracy'] else 0
print(f"Trial {i+1} - Val Acc: {val_accuracy:.4f} - Time: {training_time:.1f}s")
# Store results
result = {
'params': params.copy(),
'val_accuracy': val_accuracy,
'final_val_accuracy': final_val_acc,
'epochs_trained': len(history.history['accuracy']) if history.history.get('accuracy') else 0,
'training_time': training_time,
'trial': i + 1,
'history': history.history
}
results.append(result)
# Update best parameters
if val_accuracy > best_score:
best_score = val_accuracy
best_params = params.copy()
best_history = history
print(f"New best: {val_accuracy:.4f}")
# Cleanup
del model
K.clear_session()
self.model_config = original_config
except Exception as e:
print(f"Trial {i+1} failed: {str(e)}")
self.model_config = original_config
continue
# Sort results
results.sort(key=lambda x: x['val_accuracy'], reverse=True)
print(f"\nHyperparameter tuning completed!")
print(f"Best validation accuracy: {best_score:.4f}")
print(f"Best parameters: {best_params}")
if best_history is not None:
self.best_tuning_history = best_history
return best_params, best_score, results
def save_artifacts(self, modelfilepath, artifacts_filepath, history_filepath):
"""Save model and preprocessing artifacts"""
# Save model
self.model.save(f"{modelfilepath}.keras")
# Save artifacts
artifacts = {
'data_processor': self.data_processor,
'target_composers': self.target_composers,
'model_config': self.model_config,
'training_config': self.training_config,
'metrics': self.metrics
}
with open(artifacts_filepath, 'wb') as f:
pickle.dump(artifacts, f)
# Save history
if self.history:
with open(history_filepath, 'wb') as f:
pickle.dump(self.history.history, f)
# Utility Functions
def create_model_config(**kwargs) -> ModelConfig:
"""Create model configuration with custom parameters"""
return ModelConfig(**kwargs)
def create_training_config(**kwargs) -> TrainingConfig:
"""Create training configuration with custom parameters"""
return TrainingConfig(**kwargs)
def plot_training_history(history: tf.keras.callbacks.History, figsize: Tuple[int, int] = (15, 5)):
"""Plot training history with visualization"""
fig, axes = plt.subplots(1, 3, figsize=figsize)
# Accuracy plot
axes[0].plot(history.history['accuracy'], label='Training', linewidth=2)
axes[0].plot(history.history['val_accuracy'], label='Validation', linewidth=2)
axes[0].set_title('Model Accuracy', fontweight='bold')
axes[0].set_xlabel('Epoch')
axes[0].set_ylabel('Accuracy')
axes[0].legend()
axes[0].grid(True, alpha=0.3)
# Loss plot
axes[1].plot(history.history['loss'], label='Training', linewidth=2)
axes[1].plot(history.history['val_loss'], label='Validation', linewidth=2)
axes[1].set_title('Model Loss', fontweight='bold')
axes[1].set_xlabel('Epoch')
axes[1].set_ylabel('Loss')
axes[1].legend()
axes[1].grid(True, alpha=0.3)
# metrics summary
axes[2].axis('off')
final_acc = history.history['val_accuracy'][-1]
best_acc = max(history.history['val_accuracy'])
final_loss = history.history['val_loss'][-1]
best_loss = min(history.history['val_loss'])
summary_text = f"""
Final Validation Accuracy: {final_acc:.4f}
Best Validation Accuracy: {best_acc:.4f}
Final Validation Loss: {final_loss:.4f}
Best Validation Loss: {best_loss:.4f}
Total Epochs: {len(history.history['accuracy'])}
"""
axes[2].text(0.1, 0.9, summary_text, transform=axes[2].transAxes,
fontsize=12, verticalalignment='top',
bbox=dict(boxstyle='round', facecolor='lightgreen', alpha=0.8))
axes[2].set_title('Training Summary', fontweight='bold')
plt.tight_layout()
plt.show()
def plot_feature_importances(data_processor, features_df, feature_type='musical', top_n=15):
"""
Plot feature importances using RandomForest for the selected features.
"""
# Get selected features and data
selector_info = data_processor.feature_selectors[feature_type]
selected_features = selector_info['features']
X = features_df[selected_features].fillna(0)
y = features_df['composer']
# Fit RandomForest for importance
rf = RandomForestClassifier(n_estimators=100, random_state=42)
rf.fit(X, y)
importances = rf.feature_importances_
# Sort and plot
indices = np.argsort(importances)[::-1][:top_n]
plt.figure(figsize=(12, 6))
sns.barplot(x=np.array(selected_features)[indices], y=importances[indices], palette=env_config.color_pallete,)
plt.title(f"Top {top_n} {feature_type.capitalize()} Feature Importances")
plt.ylabel("Importance")
plt.xlabel("Feature")
plt.xticks(rotation=45, ha='right')
plt.tight_layout()
plt.show()
# Utility Functions
def create_model_config(**kwargs) -> ModelConfig:
"""Create model configuration with custom parameters"""
return ModelConfig(**kwargs)
def create_training_config(**kwargs) -> TrainingConfig:
"""Create training configuration with custom parameters"""
return TrainingConfig(**kwargs)
def plot_training_history(history: tf.keras.callbacks.History, figsize: Tuple[int, int] = (15, 5)):
"""Plot training history with visualization"""
fig, axes = plt.subplots(1, 3, figsize=figsize)
# Accuracy plot
axes[0].plot(history.history['accuracy'], label='Training', linewidth=2)
axes[0].plot(history.history['val_accuracy'], label='Validation', linewidth=2)
axes[0].set_title('Model Accuracy', fontweight='bold')
axes[0].set_xlabel('Epoch')
axes[0].set_ylabel('Accuracy')
axes[0].legend()
axes[0].grid(True, alpha=0.3)
# Loss plot
axes[1].plot(history.history['loss'], label='Training', linewidth=2)
axes[1].plot(history.history['val_loss'], label='Validation', linewidth=2)
axes[1].set_title('Model Loss', fontweight='bold')
axes[1].set_xlabel('Epoch')
axes[1].set_ylabel('Loss')
axes[1].legend()
axes[1].grid(True, alpha=0.3)
# metrics summary
axes[2].axis('off')
final_acc = history.history['val_accuracy'][-1]
best_acc = max(history.history['val_accuracy'])
final_loss = history.history['val_loss'][-1]
best_loss = min(history.history['val_loss'])
summary_text = f"""
Final Validation Accuracy: {final_acc:.4f}
Best Validation Accuracy: {best_acc:.4f}
Final Validation Loss: {final_loss:.4f}
Best Validation Loss: {best_loss:.4f}
Total Epochs: {len(history.history['accuracy'])}
"""
axes[2].text(0.1, 0.9, summary_text, transform=axes[2].transAxes,
fontsize=12, verticalalignment='top',
bbox=dict(boxstyle='round', facecolor='lightgreen', alpha=0.8))
axes[2].set_title('Training Summary', fontweight='bold')
plt.tight_layout()
plt.show()
def plot_feature_importances(data_processor, features_df, feature_type='musical', top_n=15):
"""
Plot feature importances using RandomForest for the selected features.
"""
# Get selected features and data
selector_info = data_processor.feature_selectors[feature_type]
selected_features = selector_info['features']
X = features_df[selected_features].fillna(0)
y = features_df['composer']
# Fit RandomForest for importance
rf = RandomForestClassifier(n_estimators=100, random_state=42)
rf.fit(X, y)
importances = rf.feature_importances_
# Sort and plot
indices = np.argsort(importances)[::-1][:top_n]
plt.figure(figsize=(12, 6))
sns.barplot(x=np.array(selected_features)[indices], y=importances[indices], palette=env_config.color_pallete,)
plt.title(f"Top {top_n} {feature_type.capitalize()} Feature Importances")
plt.ylabel("Importance")
plt.xlabel("Feature")
plt.xticks(rotation=45, ha='right')
plt.tight_layout()
plt.show()
# Load and Initialize Pipeline
print("Initializing Composer Classification Pipeline...")
# Create configurations optimized for minority class performance
model_config = create_model_config(
lstm_units=256,
cnn_filters=128,
dense_units=512,
dropout_rate=0.3,
learning_rate=0.00008,
attention_heads=12,
l2_regularization=0.0008
)
training_config = create_training_config(
epochs=150,
batch_size=28,
patience=25,
val_split=0.15,
test_split=0.15
)
# Initialize pipeline
pipeline = ComposerClassificationPipeline(
target_composers=TARGET_COMPOSERS,
model_config=model_config,
training_config=training_config
)
Initializing Composer Classification Pipeline...
# Data Loading and Preparation
print("\nLoading processed feature data...")
try:
# Load musical and harmonic features
if EXTRACT_FEATURES:
musical_data = features_df
harmonic_data = harmonic_df
else:
musical_data = pd.read_pickle(MUSICAL_FEATURES_DF_PATH)
harmonic_data = pd.read_pickle(HARMONIC_FEATURES_DF_PATH)
# Load note sequences and labels
note_sequences = np.load(NOTE_SEQUENCES_PATH)
sequence_labels = np.load(NOTE_SEQUENCES_LABELS_PATH)
# Load note mappings
with open(NOTE_MAPPING_PATH, 'rb') as f:
note_mappings = pickle.load(f)
print(f"Musical features loaded: {musical_data.shape}")
print(f"Harmonic features loaded: {harmonic_data.shape}")
print(f"Note sequences loaded: {note_sequences.shape}")
print(f"Sequence labels loaded: {sequence_labels.shape}")
# Map sequence labels to composer names
int_to_composer = note_mappings.get('int_to_composer', {})
if int_to_composer:
sequence_labels_mapped = [int_to_composer.get(label, f'Unknown_{label}')
for label in sequence_labels]
else:
sequence_labels_mapped = sequence_labels
print("Data loading completed successfully")
except FileNotFoundError as e:
print(f"Error: Required data files not found. {e}")
print("Please ensure feature extraction has been completed.")
raise
except Exception as e:
print(f"Error loading data: {e}")
raise
Loading processed feature data... Musical features loaded: (1630, 24) Harmonic features loaded: (1630, 51) Note sequences loaded: (68651, 100) Sequence labels loaded: (68651,) Data loading completed successfully
# Data Preparation and Feature Selection with Augmentation
print("\nDATA PREPARATION AND FEATURE SELECTION")
try:
# Prepare data splits with augmentation
data_splits = pipeline.prepare_data(
musical_df=musical_data,
harmonic_df=harmonic_data,
note_sequences=note_sequences,
sequence_labels=np.array(sequence_labels_mapped)
)
# Plot for musical features
plot_feature_importances(pipeline.data_processor, features_df, feature_type='musical', top_n=15)
# Plot for harmonic features
plot_feature_importances(pipeline.data_processor, harmonic_df, feature_type='harmonic', top_n=15)
print("Data preparation completed successfully")
print(f"Training samples: {len(data_splits['y_train'])}")
print(f"Validation samples: {len(data_splits['y_val'])}")
print(f"Test samples: {len(data_splits['y_test'])}")
# Display class distribution after augmentation
unique_labels, counts = np.unique(data_splits['y_train_encoded'], return_counts=True)
class_distribution = dict(zip([TARGET_COMPOSERS[i] for i in unique_labels], counts))
print(f"Training class distribution after augmentation: {class_distribution}")
# Calculate class balance improvement
max_count = max(counts)
min_count = min(counts)
balance_ratio = max_count / min_count
print(f"Class balance ratio (max/min): {balance_ratio:.2f}")
# Display selected features
feature_names = pipeline.data_processor.feature_selectors
if 'musical' in feature_names:
print(f"Selected musical features ({len(feature_names['musical']['features'])}): {feature_names['musical']['features'][:5]}...")
if 'harmonic' in feature_names:
print(f"Selected harmonic features ({len(feature_names['harmonic']['features'])}): {feature_names['harmonic']['features'][:5]}...")
except Exception as e:
print(f"Error in data preparation: {e}")
raise
DATA PREPARATION AND FEATURE SELECTION


Data preparation completed successfully
Training samples: 2810
Validation samples: 496
Test samples: 584
Training class distribution after augmentation: {'Bach': np.int64(739), 'Beethoven': np.int64(938), 'Chopin': np.int64(947), 'Mozart': np.int64(186)}
Class balance ratio (max/min): 5.09
Selected musical features (15): ['total_duration', 'tempo', 'avg_interval', 'num_rests', 'duration_std']...
Selected harmonic features (20): ['harmonic_rhythm_variance', 'note_density_variance', 'cadential_tonic_ratio', 'harmonic_rhythm_regularity', 'minor_chord_ratio']...
# Model Building
print("\nMODEL BUILDING")
try:
# Build the hybrid model
model = pipeline.build_model()
print("Hybrid CNN-LSTM model built successfully")
print(f"Total parameters: {model.count_params():,}")
print("Model input shapes:")
for i, input_layer in enumerate(model.inputs):
print(f"- {input_layer.name}: {input_layer.shape}")
print(f"Model output shape: {model.output.shape}")
# Display model summary
print("\nModel Architecture Summary:")
model.summary(line_length=100)
except Exception as e:
print(f"Error building model: {e}")
raise
\MODEL BUILDING Hybrid CNN-LSTM model built successfully Total parameters: 4,701,700 Model input shapes: - musical_features: (None, 15) - harmonic_features: (None, 20) - sequence_features: (None, 120) Model output shape: (None, 4) Model Architecture Summary:
Model: "HybridComposerClassifier"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ Connected to ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━┩ │ sequence_features │ (None, 120) │ 0 │ - │ │ (InputLayer) │ │ │ │ ├─────────────────────────────┼─────────────────────────┼────────────────┼─────────────────────────┤ │ cnn_reshape (Reshape) │ (None, 120, 1) │ 0 │ sequence_features[0][0] │ ├─────────────────────────────┼─────────────────────────┼────────────────┼─────────────────────────┤ │ cnn_branch_conv_1 (Conv1D) │ (None, 120, 128) │ 1,024 │ cnn_reshape[0][0] │ ├─────────────────────────────┼─────────────────────────┼────────────────┼─────────────────────────┤ │ cnn_branch_ln_1 │ (None, 120, 128) │ 256 │ cnn_branch_conv_1[0][0] │ │ (LayerNormalization) │ │ │ │ ├─────────────────────────────┼─────────────────────────┼────────────────┼─────────────────────────┤ │ cnn_branch_pool_1 │ (None, 60, 128) │ 0 │ cnn_branch_ln_1[0][0] │ │ (MaxPooling1D) │ │ │ │ ├─────────────────────────────┼─────────────────────────┼────────────────┼─────────────────────────┤ │ cnn_branch_dropout_1 │ (None, 60, 128) │ 0 │ cnn_branch_pool_1[0][0] │ │ (Dropout) │ │ │ │ ├─────────────────────────────┼─────────────────────────┼────────────────┼─────────────────────────┤ │ cnn_branch_separable_conv │ (None, 60, 256) │ 33,664 │ cnn_branch_dropout_1[0… │ │ (SeparableConv1D) │ │ │ │ ├─────────────────────────────┼─────────────────────────┼────────────────┼─────────────────────────┤ │ cnn_branch_ln_2 │ (None, 60, 256) │ 512 │ cnn_branch_separable_c… │ │ (LayerNormalization) │ │ │ │ ├─────────────────────────────┼─────────────────────────┼────────────────┼─────────────────────────┤ │ cnn_residual_projection │ (None, 60, 256) │ 33,024 │ cnn_branch_dropout_1[0… │ │ (Conv1D) │ │ │ │ ├─────────────────────────────┼─────────────────────────┼────────────────┼─────────────────────────┤ │ cnn_residual_add (Add) │ (None, 60, 256) │ 0 │ cnn_branch_ln_2[0][0], │ │ │ │ │ cnn_residual_projectio… │ ├─────────────────────────────┼─────────────────────────┼────────────────┼─────────────────────────┤ │ cnn_residual_activation │ (None, 60, 256) │ 0 │ cnn_residual_add[0][0] │ │ (Activation) │ │ │ │ ├─────────────────────────────┼─────────────────────────┼────────────────┼─────────────────────────┤ │ musical_features │ (None, 15) │ 0 │ - │ │ (InputLayer) │ │ │ │ ├─────────────────────────────┼─────────────────────────┼────────────────┼─────────────────────────┤ │ harmonic_features │ (None, 20) │ 0 │ - │ │ (InputLayer) │ │ │ │ ├─────────────────────────────┼─────────────────────────┼────────────────┼─────────────────────────┤ │ cnn_branch_dropout_2 │ (None, 60, 256) │ 0 │ cnn_residual_activatio… │ │ (Dropout) │ │ │ │ ├─────────────────────────────┼─────────────────────────┼────────────────┼─────────────────────────┤ │ musical_dense_1 (Dense) │ (None, 512) │ 8,192 │ musical_features[0][0] │ ├─────────────────────────────┼─────────────────────────┼────────────────┼─────────────────────────┤ │ harmonic_dense_1 (Dense) │ (None, 512) │ 10,752 │ harmonic_features[0][0] │ ├─────────────────────────────┼─────────────────────────┼────────────────┼─────────────────────────┤ │ lstm_branch_1 │ (None, 60, 512) │ 1,050,624 │ cnn_branch_dropout_2[0… │ │ (Bidirectional) │ │ │ │ ├─────────────────────────────┼─────────────────────────┼────────────────┼─────────────────────────┤ │ musical_ln_1 │ (None, 512) │ 1,024 │ musical_dense_1[0][0] │ │ (LayerNormalization) │ │ │ │ ├─────────────────────────────┼─────────────────────────┼────────────────┼─────────────────────────┤ │ harmonic_ln_1 │ (None, 512) │ 1,024 │ harmonic_dense_1[0][0] │ │ (LayerNormalization) │ │ │ │ ├─────────────────────────────┼─────────────────────────┼────────────────┼─────────────────────────┤ │ multi_head_attention │ (None, 60, 512) │ 788,096 │ lstm_branch_1[0][0], │ │ (MultiHeadAttention) │ │ │ lstm_branch_1[0][0] │ ├─────────────────────────────┼─────────────────────────┼────────────────┼─────────────────────────┤ │ musical_dropout_1 (Dropout) │ (None, 512) │ 0 │ musical_ln_1[0][0] │ ├─────────────────────────────┼─────────────────────────┼────────────────┼─────────────────────────┤ │ harmonic_dropout_1 │ (None, 512) │ 0 │ harmonic_ln_1[0][0] │ │ (Dropout) │ │ │ │ ├─────────────────────────────┼─────────────────────────┼────────────────┼─────────────────────────┤ │ attention_residual (Add) │ (None, 60, 512) │ 0 │ lstm_branch_1[0][0], │ │ │ │ │ multi_head_attention[0… │ ├─────────────────────────────┼─────────────────────────┼────────────────┼─────────────────────────┤ │ musical_dense_2 (Dense) │ (None, 256) │ 131,328 │ musical_dropout_1[0][0] │ ├─────────────────────────────┼─────────────────────────┼────────────────┼─────────────────────────┤ │ musical_skip_projection │ (None, 256) │ 4,096 │ musical_features[0][0] │ │ (Dense) │ │ │ │ ├─────────────────────────────┼─────────────────────────┼────────────────┼─────────────────────────┤ │ harmonic_dense_2 (Dense) │ (None, 256) │ 131,328 │ harmonic_dropout_1[0][… │ ├─────────────────────────────┼─────────────────────────┼────────────────┼─────────────────────────┤ │ harmonic_skip_projection │ (None, 256) │ 5,376 │ harmonic_features[0][0] │ │ (Dense) │ │ │ │ ├─────────────────────────────┼─────────────────────────┼────────────────┼─────────────────────────┤ │ attention_norm │ (None, 60, 512) │ 1,024 │ attention_residual[0][… │ │ (LayerNormalization) │ │ │ │ ├─────────────────────────────┼─────────────────────────┼────────────────┼─────────────────────────┤ │ musical_skip_add (Add) │ (None, 256) │ 0 │ musical_dense_2[0][0], │ │ │ │ │ musical_skip_projectio… │ ├─────────────────────────────┼─────────────────────────┼────────────────┼─────────────────────────┤ │ harmonic_skip_add (Add) │ (None, 256) │ 0 │ harmonic_dense_2[0][0], │ │ │ │ │ harmonic_skip_projecti… │ ├─────────────────────────────┼─────────────────────────┼────────────────┼─────────────────────────┤ │ attention_dropout (Dropout) │ (None, 60, 512) │ 0 │ attention_norm[0][0] │ ├─────────────────────────────┼─────────────────────────┼────────────────┼─────────────────────────┤ │ musical_ln_2 │ (None, 256) │ 512 │ musical_skip_add[0][0] │ │ (LayerNormalization) │ │ │ │ ├─────────────────────────────┼─────────────────────────┼────────────────┼─────────────────────────┤ │ harmonic_ln_2 │ (None, 256) │ 512 │ harmonic_skip_add[0][0] │ │ (LayerNormalization) │ │ │ │ ├─────────────────────────────┼─────────────────────────┼────────────────┼─────────────────────────┤ │ lstm_branch_2 │ (None, 60, 256) │ 656,384 │ attention_dropout[0][0] │ │ (Bidirectional) │ │ │ │ ├─────────────────────────────┼─────────────────────────┼────────────────┼─────────────────────────┤ │ musical_dropout_2 (Dropout) │ (None, 256) │ 0 │ musical_ln_2[0][0] │ ├─────────────────────────────┼─────────────────────────┼────────────────┼─────────────────────────┤ │ harmonic_dropout_2 │ (None, 256) │ 0 │ harmonic_ln_2[0][0] │ │ (Dropout) │ │ │ │ ├─────────────────────────────┼─────────────────────────┼────────────────┼─────────────────────────┤ │ lstm_global_pool │ (None, 256) │ 0 │ lstm_branch_2[0][0] │ │ (GlobalAveragePooling1D) │ │ │ │ ├─────────────────────────────┼─────────────────────────┼────────────────┼─────────────────────────┤ │ feature_concatenation │ (None, 768) │ 0 │ musical_dropout_2[0][0… │ │ (Concatenate) │ │ │ harmonic_dropout_2[0][… │ │ │ │ │ lstm_global_pool[0][0] │ ├─────────────────────────────┼─────────────────────────┼────────────────┼─────────────────────────┤ │ feature_alignment (Dense) │ (None, 512) │ 393,728 │ feature_concatenation[… │ ├─────────────────────────────┼─────────────────────────┼────────────────┼─────────────────────────┤ │ cross_attention_norm │ (None, 512) │ 1,024 │ feature_alignment[0][0] │ │ (LayerNormalization) │ │ │ │ ├─────────────────────────────┼─────────────────────────┼────────────────┼─────────────────────────┤ │ reshape (Reshape) │ (None, 1, 512) │ 0 │ cross_attention_norm[0… │ ├─────────────────────────────┼─────────────────────────┼────────────────┼─────────────────────────┤ │ cross_feature_attention │ (None, 1, 512) │ 1,050,624 │ reshape[0][0], │ │ (MultiHeadAttention) │ │ │ reshape[0][0] │ ├─────────────────────────────┼─────────────────────────┼────────────────┼─────────────────────────┤ │ flatten (Flatten) │ (None, 512) │ 0 │ cross_feature_attentio… │ ├─────────────────────────────┼─────────────────────────┼────────────────┼─────────────────────────┤ │ cross_attention_residual │ (None, 512) │ 0 │ cross_attention_norm[0… │ │ (Add) │ │ │ flatten[0][0] │ ├─────────────────────────────┼─────────────────────────┼────────────────┼─────────────────────────┤ │ cross_attention_final_norm │ (None, 512) │ 1,024 │ cross_attention_residu… │ │ (LayerNormalization) │ │ │ │ ├─────────────────────────────┼─────────────────────────┼────────────────┼─────────────────────────┤ │ classifier_dense_1 (Dense) │ (None, 512) │ 262,656 │ cross_attention_final_… │ ├─────────────────────────────┼─────────────────────────┼────────────────┼─────────────────────────┤ │ classifier_ln_1 │ (None, 512) │ 1,024 │ classifier_dense_1[0][… │ │ (LayerNormalization) │ │ │ │ ├─────────────────────────────┼─────────────────────────┼────────────────┼─────────────────────────┤ │ classifier_dropout_1 │ (None, 512) │ 0 │ classifier_ln_1[0][0] │ │ (Dropout) │ │ │ │ ├─────────────────────────────┼─────────────────────────┼────────────────┼─────────────────────────┤ │ classifier_dense_2 (Dense) │ (None, 256) │ 131,328 │ classifier_dropout_1[0… │ ├─────────────────────────────┼─────────────────────────┼────────────────┼─────────────────────────┤ │ classifier_ln_2 │ (None, 256) │ 512 │ classifier_dense_2[0][… │ │ (LayerNormalization) │ │ │ │ ├─────────────────────────────┼─────────────────────────┼────────────────┼─────────────────────────┤ │ classifier_dropout_2 │ (None, 256) │ 0 │ classifier_ln_2[0][0] │ │ (Dropout) │ │ │ │ ├─────────────────────────────┼─────────────────────────┼────────────────┼─────────────────────────┤ │ composer_predictions │ (None, 4) │ 1,028 │ classifier_dropout_2[0… │ │ (Dense) │ │ │ │ └─────────────────────────────┴─────────────────────────┴────────────────┴─────────────────────────┘
Total params: 4,701,700 (17.94 MB)
Trainable params: 4,701,700 (17.94 MB)
Non-trainable params: 0 (0.00 B)
print("\nMODEL ARCHITECTURE VISUALIZATION")
try:
from tensorflow.keras.utils import plot_model
# Create the model architecture diagram
print("Generating model architecture diagram...")
# Plot the model architecture with detailed information
plot_model(
pipeline.model,
to_file='data/model/model_architecture.png',
show_shapes=True,
dpi=300
)
except Exception as e:
print(f"Error generating model architecture visualization: {e}")
MODEL ARCHITECTURE VISUALIZATION Generating model architecture diagram...
# Model Training
print("MODEL TRAINING")
try:
# Display training configuration
print("Training Configuration:")
print(f"- Epochs: {training_config.epochs}")
print(f"- Batch size: {training_config.batch_size}")
print(f"- Learning rate: {model_config.learning_rate}")
print(f"- Early stopping patience: {training_config.patience}")
print(f"- Dropout rate: {model_config.dropout_rate}")
print(f"- L2 regularization: {model_config.l2_regularization}")
print(f"- Attention heads: {model_config.attention_heads}")
# Check GPU availability
if tf.config.list_physical_devices('GPU'):
print("GPU acceleration available")
# Configure GPU memory growth
gpus = tf.config.experimental.list_physical_devices('GPU')
if gpus:
try:
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
print("GPU memory growth configured")
except RuntimeError as e:
print(f"GPU configuration warning: {e}")
else:
print("Using CPU for training")
# Display class weights
class_weights = pipeline.compute_class_weights(data_splits['y_train_encoded'])
print(f"Class weights: {class_weights}")
# Start training
print("\nStarting model training...")
start_time = time.time()
history = pipeline.train(data_splits)
training_time = time.time() - start_time
print("\nModel training completed successfully!")
print(f"Total training time: {training_time:.2f} seconds ({training_time/60:.2f} minutes)")
# Model training summary
final_train_acc = history.history['accuracy'][-1]
final_val_acc = history.history['val_accuracy'][-1]
best_val_acc = max(history.history['val_accuracy'])
final_train_loss = history.history['loss'][-1]
final_val_loss = history.history['val_loss'][-1]
best_val_loss = min(history.history['val_loss'])
print("\nModel Training Results Summary:")
print(f"- Final training accuracy: {final_train_acc:.4f}")
print(f"- Final validation accuracy: {final_val_acc:.4f}")
print(f"- Best validation accuracy: {best_val_acc:.4f}")
print(f"- Final training loss: {final_train_loss:.4f}")
print(f"- Final validation loss: {final_val_loss:.4f}")
print(f"- Best validation loss: {best_val_loss:.4f}")
print(f"- Total epochs trained: {len(history.history['accuracy'])}")
# Check for overfitting
train_val_gap = final_train_acc - final_val_acc
if train_val_gap > 0.1:
print(f"Warning: Potential overfitting detected (train-val gap: {train_val_gap:.4f})")
else:
print(f"Good generalization achieved (train-val gap: {train_val_gap:.4f})")
# Plot training history
print("Generating training history plots...")
plot_training_history(history, figsize=(18, 6))
except Exception as e:
print(f"Error during training: {e}")
raise
MODEL TRAINING
Training Configuration:
- Epochs: 150
- Batch size: 28
- Learning rate: 8e-05
- Early stopping patience: 25
- Dropout rate: 0.3
- L2 regularization: 0.0008
- Attention heads: 12
Using CPU for training
Class weights: {np.int64(0): np.float64(1.0456698240866036), np.int64(1): np.float64(2.0970149253731343), np.int64(2): np.float64(2.3738120380147834), np.int64(3): np.float64(3.7768817204301075)}
Starting model training...
Training Model: 49%|████▉ | 74/150 [29:30<30:18, 23.93s/it, loss=2.3773, acc=0.9940, val_acc=0.9657, lr=0.0000000]
Model training completed successfully! Total training time: 1770.66 seconds (29.51 minutes) Model Training Results Summary: - Final training accuracy: 0.9940 - Final validation accuracy: 0.9657 - Best validation accuracy: 0.9758 - Final training loss: 2.3773 - Final validation loss: 1.6724 - Best validation loss: 1.6724 - Total epochs trained: 74 Good generalization achieved (train-val gap: 0.0282) Generating training history plots...

Model Training Interpretation¶
High Performance: The model achieved a final training accuracy of 99.40% and a final validation accuracy of 96.57%, with the best validation accuracy reaching 97.58%.
Loss Reduction: Training and validation losses decreased steadily, with the best validation loss at 1.6724.
Generalization: The small train–validation accuracy gap (~2.82%) indicates good generalization and minimal overfitting.
Training Efficiency: Early stopping triggered at 74 epochs out of 150, avoiding unnecessary training while maintaining strong performance.
Stability: Accuracy and loss curves are smooth, suggesting stable learning without significant oscillations.
Configuration Highlights:
- Learning rate:
8e-05 - Dropout:
0.3 - L2 regularization:
0.0008 - Attention heads:
12 - Batch size:
28 - Class weights applied to address class imbalance.
- Learning rate:
# Model Evaluation
print("\nMODEL EVALUATION")
try:
# Evaluate model on test set
print("Evaluating model on test set...")
test_metrics = pipeline.evaluate(data_splits)
print("\nTest Results:")
print(f"- Test Accuracy: {test_metrics['accuracy']:.4f}")
print(f"- Test Precision: {test_metrics['precision']:.4f}")
print(f"- Test Recall: {test_metrics['recall']:.4f}")
print(f"- Test F1-Score: {test_metrics['f1_score']:.4f}")
# Per-class performance in table format
print("\nPer-Class Performance Table:")
# Create a list to store the performance data
performance_data = []
for composer in TARGET_COMPOSERS:
if composer in test_metrics['classification_report']:
metrics = test_metrics['classification_report'][composer]
auc_score = test_metrics['roc_data'][composer]['auc'] if composer in test_metrics['roc_data'] else 'N/A'
performance_data.append({
'Composer': composer,
'Precision': f"{metrics['precision']:.4f}",
'Recall': f"{metrics['recall']:.4f}",
'F1-Score': f"{metrics['f1-score']:.4f}",
'AUC': f"{auc_score:.4f}" if auc_score != 'N/A' else 'N/A',
'Support': metrics['support']
})
# Create DataFrame and display as table
performance_df = pd.DataFrame(performance_data)
print(performance_df.to_string(index=False))
print("\nModel evaluation completed successfully!")
except Exception as e:
print(f"Error during evaluation: {e}")
raise
MODEL EVALUATION
Evaluating model on test set...
Test Results:
- Test Accuracy: 0.9675
- Test Precision: 0.9675
- Test Recall: 0.9675
- Test F1-Score: 0.9674
Per-Class Performance Table:
Composer Precision Recall F1-Score AUC Support
Bach 0.9675 0.9675 0.9675 0.9980 154.0
Beethoven 0.9598 0.9795 0.9695 0.9967 195.0
Chopin 0.9897 0.9746 0.9821 0.9987 197.0
Mozart 0.8919 0.8684 0.8800 0.9962 38.0
Model evaluation completed successfully!
# Visualization of Results
print("\nRESULTS VISUALIZATION")
try:
# Get viridis color palette
viridis_colors = sns.color_palette(env_config.color_pallete, len(TARGET_COMPOSERS))
# Plot confusion matrix
print("Generating confusion matrix...")
plt.figure(figsize=(10, 8))
# Normalized confusion matrix
cm = test_metrics['confusion_matrix']
cm_normalized = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
plt.subplot(1, 2, 1)
sns.heatmap(cm, annot=True, fmt='d', cmap='viridis',
xticklabels=TARGET_COMPOSERS, yticklabels=TARGET_COMPOSERS)
plt.title('Confusion Matrix (Counts)', fontweight='bold')
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.subplot(1, 2, 2)
sns.heatmap(cm_normalized, annot=True, fmt='.3f', cmap='viridis',
xticklabels=TARGET_COMPOSERS, yticklabels=TARGET_COMPOSERS)
plt.title('Confusion Matrix (Normalized)', fontweight='bold')
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.tight_layout()
plt.show()
# Plot ROC curves
print("Generating ROC curves...")
plt.figure(figsize=(10, 8))
# Use viridis colors for ROC curves
for i, (composer, data) in enumerate(test_metrics['roc_data'].items()):
color = viridis_colors[i % len(viridis_colors)]
plt.plot(data['fpr'], data['tpr'], color=color, linewidth=2,
label=f'{composer} (AUC = {data["auc"]:.3f})')
plt.plot([0, 1], [0, 1], 'k--', linewidth=1, alpha=0.8)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate', fontweight='bold')
plt.ylabel('True Positive Rate', fontweight='bold')
plt.title('ROC Curves by Composer', fontsize=16, fontweight='bold')
plt.legend(loc="lower right")
plt.grid(True, alpha=0.3)
plt.show()
# Performance comparison chart
print("Generating performance comparison...")
fig, axes = plt.subplots(1, 2, figsize=(16, 6))
# Per-class metrics using viridis colors
composers = [c for c in TARGET_COMPOSERS if c in test_metrics['classification_report']]
metrics_names = ['precision', 'recall', 'f1-score']
x = np.arange(len(composers))
width = 0.25
# Use different viridis shades for each metric
metric_colors = sns.color_palette(env_config.color_pallete, len(metrics_names))
for i, metric in enumerate(metrics_names):
values = [test_metrics['classification_report'][comp][metric] for comp in composers]
bars = axes[0].bar(x + i*width, values, width, label=metric.title(),
alpha=0.8, color=metric_colors[i])
# Add value labels on bars
for bar, value in zip(bars, values):
height = bar.get_height()
axes[0].text(bar.get_x() + bar.get_width()/2., height + 0.01,
f'{value:.3f}', ha='center', va='bottom', fontsize=9, fontweight='bold')
axes[0].set_xlabel('Composer', fontweight='bold')
axes[0].set_ylabel('Score', fontweight='bold')
axes[0].set_title('Per-Class Performance Metrics', fontweight='bold')
axes[0].set_xticks(x + width)
axes[0].set_xticklabels(composers, rotation=45)
axes[0].legend()
axes[0].grid(True, alpha=0.3)
# AUC comparison using viridis colors
auc_scores = [test_metrics['roc_data'][comp]['auc'] for comp in composers]
bars = axes[1].bar(composers, auc_scores, color=viridis_colors[:len(composers)], alpha=0.7)
axes[1].set_xlabel('Composer', fontweight='bold')
axes[1].set_ylabel('AUC Score', fontweight='bold')
axes[1].set_title('AUC Scores by Composer', fontweight='bold')
axes[1].set_ylim([0, 1])
axes[1].grid(True, alpha=0.3)
# Add value labels on bars
for bar, score in zip(bars, auc_scores):
height = bar.get_height()
axes[1].text(bar.get_x() + bar.get_width()/2., height + 0.01,
f'{score:.3f}', ha='center', va='bottom', fontweight='bold')
plt.tight_layout()
plt.show()
print("Visualization completed successfully!")
except Exception as e:
print(f"Error during visualization: {e}")
RESULTS VISUALIZATION Generating confusion matrix...

Generating ROC curves...

Generating performance comparison...

Visualization completed successfully!
try:
# Display final summary
print("\nPIPELINE EXECUTION SUMMARY")
print(f"Model built with {pipeline.model.count_params():,} parameters")
print(f"Training completed in {len(pipeline.history.history['accuracy'])} epochs")
print(f"Best validation accuracy: {max(pipeline.history.history['val_accuracy']):.4f}")
print(f"Test accuracy: {test_metrics['accuracy']:.4f}")
print("Model artifacts saved for deployment")
print("\nFinal Performance Metrics:")
print(f"- Accuracy: {test_metrics['accuracy']:.4f}")
print(f"- Precision: {test_metrics['precision']:.4f}")
print(f"- Recall: {test_metrics['recall']:.4f}")
print(f"- F1-Score: {test_metrics['f1_score']:.4f}")
except Exception as e:
print(f"Error during model saving: {e}")
PIPELINE EXECUTION SUMMARY Model built with 4,701,700 parameters Training completed in 74 epochs Best validation accuracy: 0.9758 Test accuracy: 0.9675 Model artifacts saved for deployment Final Performance Metrics: - Accuracy: 0.9675 - Precision: 0.9675 - Recall: 0.9675 - F1-Score: 0.9674
Model Training & Evaluation Interpretation¶
1. Training Performance¶
- The model reached a final training accuracy of 99.40% and a final validation accuracy of 96.57%, with the best validation accuracy at 97.58%.
- The train–validation accuracy gap of about 2.82% indicates minimal overfitting and strong generalization.
- Final training loss was 2.3773, and final validation loss was 1.6724, both showing steady and stable decline throughout training.
- Early stopping triggered at 74 epochs (out of 150) prevented unnecessary computation while retaining peak performance.
- Key training parameters included a learning rate of
8e-05, batch size of 28, dropout rate of 0.3, L2 regularization of 0.0008, and 12 attention heads. Class weights were applied to address class imbalance.
2. Test Set Evaluation¶
- On the unseen test set, the model achieved 96.75% accuracy, precision, recall, and F1-score, showing strong generalization from the training and validation phases.
- Performance was stable across metrics, indicating consistent predictive capability.
3. Per-Class Insights¶
- Bach predictions showed high and balanced precision and recall, with excellent discriminative ability (AUC 0.998).
- Beethoven had slightly lower precision than recall, indicating a tendency to favor recall and minimize false negatives.
- Chopin achieved the highest precision and F1-score, showing very confident and correct predictions with the highest AUC of 0.999.
- Mozart had the lowest precision and recall, with most misclassifications occurring as Bach. This is likely influenced by fewer training and test samples for Mozart.
4. Confusion Matrix Observations¶
- Predictions are strongly concentrated along the diagonal, confirming correct classification for most samples.
- Misclassifications are minimal, with the most frequent being Mozart labeled as Bach.
- Confusion between Bach, Beethoven, and Chopin is rare, highlighting clear stylistic separability for these composers.
5. ROC Curve Analysis¶
- All composers achieved AUC scores above 0.996, indicating exceptional discriminative power.
- Chopin (0.999) and Bach (0.998) showed the strongest class separation.
- ROC curves are near the top-left corner, confirming low false positive rates and high true positive rates for all classes.
6. Strengths¶
- High accuracy, precision, recall, and F1-score across training, validation, and test sets.
- Minimal overfitting due to effective regularization and early stopping.
- Excellent class separation with consistently high AUC scores.
- Robust performance despite class imbalance.
7. Areas for Improvement¶
- Mozart classification performance can be improved through:
- Augmenting Mozart’s dataset to address its low sample size.
- Feature engineering tailored to Mozart’s stylistic patterns.
- Experimenting with focal loss or further class-weight tuning to penalize Mozart misclassification.
Based on these improvement areas, hyperparameter tuning will be performed to further optimize the model’s performance.
# Hyperparameter Tuning
print("\nHYPERPARAMETER TUNING")
print("Starting hyperparameter tuning with expanded search...")
# Expanded parameter grid for more granular search
param_grid = {
'lstm_units': [128, 256],
'cnn_filters': [64, 128],
'dense_units': [256, 512],
'dropout_rate': [0.25],
'learning_rate': [0.001]
}
print(f"Parameter combinations to test: {np.prod([len(v) for v in param_grid.values()])}")
# Use moderate epochs for tuning
max_trials = 4
tuning_epochs = 5
tuning_patience = 2
tuning_pipeline = ComposerClassificationPipeline(
target_composers=TARGET_COMPOSERS,
model_config=ModelConfig(),
training_config=TrainingConfig(epochs=tuning_epochs, patience=tuning_patience)
)
# Prepare data for tuning
print("Preparing data for tuning...")
tuning_data_splits = tuning_pipeline.prepare_data(
musical_df=musical_data,
harmonic_df=harmonic_data,
note_sequences=note_sequences,
sequence_labels=np.array(sequence_labels_mapped)
)
# Track best per-composer validation accuracy
best_per_composer = {composer: {'val_accuracy': 0, 'params': None} for composer in TARGET_COMPOSERS}
# Perform hyperparameter search
best_params, best_score, all_results = tuning_pipeline.tune_hyperparameters(
X_train=tuning_data_splits['X_train'],
y_train=tuning_data_splits['y_train'],
X_val=tuning_data_splits['X_val'],
y_val=tuning_data_splits['y_val'],
param_grid=param_grid,
max_trials=max_trials
)
# Analyze per-composer validation accuracy
for result in all_results:
if 'val_class_accuracies' in result:
for composer, acc in result['val_class_accuracies'].items():
if acc > best_per_composer[composer]['val_accuracy']:
best_per_composer[composer]['val_accuracy'] = acc
best_per_composer[composer]['params'] = result['params']
print("\nHyperparameter tuning completed!")
print(f"Best overall validation accuracy: {best_score:.4f}")
print(f"Best overall parameters: {best_params}")
# Display top 3 configurations
print("\nTop 3 Parameter Configurations:")
for i, result in enumerate(all_results[:3], 1):
print(f"{i}. Val Acc: {result['val_accuracy']:.4f}")
print(f"Parameters: {result['params']}")
print()
# Display best parameters per composer
print("\nBest Validation Accuracy Per Composer:")
for composer in TARGET_COMPOSERS:
acc = best_per_composer[composer]['val_accuracy']
params = best_per_composer[composer]['params']
print(f"{composer}: {acc:.4f} | Params: {params}")
# Train final model with best overall parameters
print("Training final model with best parameters...")
best_model_config = create_model_config(**best_params)
final_training_config = create_training_config(
epochs=100,
batch_size=28,
patience=20,
val_split=0.15,
test_split=0.15
)
final_pipeline = ComposerClassificationPipeline(
target_composers=TARGET_COMPOSERS,
model_config=best_model_config,
training_config=final_training_config
)
final_data_splits = final_pipeline.prepare_data(
musical_df=musical_data,
harmonic_df=harmonic_data,
note_sequences=note_sequences,
sequence_labels=np.array(sequence_labels_mapped)
)
final_model = final_pipeline.build_model()
final_history = final_pipeline.train(final_data_splits)
final_metrics = final_pipeline.evaluate(final_data_splits)
print("\nFinal model training completed!")
print(f"Test accuracy with best params: {final_metrics['accuracy']:.4f}")
print(f"Improvement over default: {final_metrics['accuracy'] - test_metrics['accuracy']:.4f}")
HYPERPARAMETER TUNING Starting hyperparameter tuning with expanded search... Parameter combinations to test: 8 Preparing data for tuning... Starting hyperparameter tuning with 4 trials... Using data subset: 563 samples for faster tuning Testing 4 parameter combinations...
Hyperparameter Search: 0%| | 0/4 [00:00<?, ?it/s]
Trial 1/4: {'lstm_units': 128, 'cnn_filters': 64, 'dense_units': 512, 'dropout_rate': 0.25, 'learning_rate': 0.001}
Trial 1 - Val Acc: 0.8471 - Time: 40.6s
New best: 0.8471
Hyperparameter Search: 25%|██▌ | 1/4 [00:44<02:14, 44.84s/it]
Trial 2/4: {'lstm_units': 256, 'cnn_filters': 64, 'dense_units': 512, 'dropout_rate': 0.25, 'learning_rate': 0.001}
Trial 2 - Val Acc: 0.8290 - Time: 48.8s
Hyperparameter Search: 50%|█████ | 2/4 [01:37<01:38, 49.29s/it]
Trial 3/4: {'lstm_units': 128, 'cnn_filters': 64, 'dense_units': 256, 'dropout_rate': 0.25, 'learning_rate': 0.001}
Trial 3 - Val Acc: 0.7847 - Time: 33.3s
Hyperparameter Search: 75%|███████▌ | 3/4 [02:14<00:43, 43.86s/it]
Trial 4/4: {'lstm_units': 256, 'cnn_filters': 128, 'dense_units': 512, 'dropout_rate': 0.25, 'learning_rate': 0.001}
Trial 4 - Val Acc: 0.8431 - Time: 62.8s
Hyperparameter Search: 100%|██████████| 4/4 [03:22<00:00, 50.56s/it]
Hyperparameter tuning completed!
Best validation accuracy: 0.8471
Best parameters: {'lstm_units': 128, 'cnn_filters': 64, 'dense_units': 512, 'dropout_rate': 0.25, 'learning_rate': 0.001}
Hyperparameter tuning completed!
Best overall validation accuracy: 0.8471
Best overall parameters: {'lstm_units': 128, 'cnn_filters': 64, 'dense_units': 512, 'dropout_rate': 0.25, 'learning_rate': 0.001}
Top 3 Parameter Configurations:
1. Val Acc: 0.8471
Parameters: {'lstm_units': 128, 'cnn_filters': 64, 'dense_units': 512, 'dropout_rate': 0.25, 'learning_rate': 0.001}
2. Val Acc: 0.8431
Parameters: {'lstm_units': 256, 'cnn_filters': 128, 'dense_units': 512, 'dropout_rate': 0.25, 'learning_rate': 0.001}
3. Val Acc: 0.8290
Parameters: {'lstm_units': 256, 'cnn_filters': 64, 'dense_units': 512, 'dropout_rate': 0.25, 'learning_rate': 0.001}
Best Validation Accuracy Per Composer:
Bach: 0.0000 | Params: None
Beethoven: 0.0000 | Params: None
Chopin: 0.0000 | Params: None
Mozart: 0.0000 | Params: None
Training final model with best parameters...
Training Model: 81%|████████ | 81/100 [32:30<07:37, 24.08s/it, loss=1.4974, acc=0.9968, val_acc=0.9556, lr=0.0000000]
Final model training completed! Test accuracy with best params: 0.9469 Improvement over default: -0.0205
def plot_model_comparison(test_metrics, final_metrics, viridis_colors):
"""Plot overall model performance comparison"""
metrics_comparison = {
'Default Model': [test_metrics['accuracy'], test_metrics['precision'],
test_metrics['recall'], test_metrics['f1_score']],
'Tuned Model': [final_metrics['accuracy'], final_metrics['precision'],
final_metrics['recall'], final_metrics['f1_score']]
}
x = np.arange(4)
width = 0.35
metric_names = ['Accuracy', 'Precision', 'Recall', 'F1-Score']
plt.bar(x - width/2, metrics_comparison['Default Model'], width,
label='Default Model', alpha=0.8, color=viridis_colors[0])
plt.bar(x + width/2, metrics_comparison['Tuned Model'], width,
label='Tuned Model', alpha=0.8, color=viridis_colors[2])
plt.xlabel('Metrics')
plt.ylabel('Score')
plt.title('Overall Model Performance Comparison')
plt.xticks(x, metric_names)
plt.legend()
plt.grid(True, alpha=0.3)
plt.ylim(0, 1)
# Add value labels on bars
for i, (default_val, tuned_val) in enumerate(zip(metrics_comparison['Default Model'], metrics_comparison['Tuned Model'])):
plt.text(i - width/2, default_val + 0.01, f'{default_val:.3f}', ha='center', va='bottom', fontsize=9)
plt.text(i + width/2, tuned_val + 0.01, f'{tuned_val:.3f}', ha='center', va='bottom', fontsize=9)
def plot_composer_performance(metrics, viridis_colors, title, subplot_position=None):
"""Plot F1-score performance by composer using viridis palette"""
if subplot_position:
plt.subplot(*subplot_position)
try:
composers = [c for c in TARGET_COMPOSERS if c in metrics['classification_report']]
if composers:
f1_scores = [metrics['classification_report'][comp]['f1-score'] for comp in composers]
# Use viridis colors for composers - map each composer to a specific viridis color
colors = [viridis_colors[i % len(viridis_colors)] for i in range(len(composers))]
bars = plt.bar(range(len(composers)), f1_scores, alpha=0.8, color=colors)
plt.xlabel('Composers')
plt.ylabel('F1-Score')
plt.title(title)
plt.xticks(range(len(composers)), composers, rotation=45, ha='right')
plt.grid(True, alpha=0.3)
plt.ylim(0, 1)
# Add value labels on bars
for bar, score in zip(bars, f1_scores):
plt.text(bar.get_x() + bar.get_width()/2, bar.get_height() + 0.01,
f'{score:.3f}', ha='center', va='bottom', fontsize=8)
else:
plt.text(0.5, 0.5, 'Classification report not available', ha='center', va='center', transform=plt.gca().transAxes)
plt.title(title)
except Exception as e:
plt.text(0.5, 0.5, f'Error: {str(e)}', ha='center', va='center', transform=plt.gca().transAxes)
plt.title(title)
def plot_improvement_analysis(test_metrics, final_metrics, viridis_colors):
"""Plot improvement analysis by composer"""
try:
composers = [c for c in TARGET_COMPOSERS if c in test_metrics['classification_report'] and c in final_metrics['classification_report']]
if composers:
improvements = []
for comp in composers:
default_f1 = test_metrics['classification_report'][comp]['f1-score']
tuned_f1 = final_metrics['classification_report'][comp]['f1-score']
improvement = tuned_f1 - default_f1
improvements.append(improvement)
# Use viridis colors for improvement visualization
colors = [viridis_colors[6] if imp >= 0 else viridis_colors[1] for imp in improvements]
bars = plt.bar(range(len(composers)), improvements, alpha=0.8, color=colors)
plt.xlabel('Composers')
plt.ylabel('F1-Score Improvement')
plt.title('Model Improvement by Composer')
plt.xticks(range(len(composers)), composers, rotation=45, ha='right')
plt.grid(True, alpha=0.3)
plt.axhline(y=0, color='black', linestyle='-', alpha=0.5)
# Add value labels on bars
for bar, improvement in zip(bars, improvements):
y_pos = bar.get_height() + 0.005 if bar.get_height() >= 0 else bar.get_height() - 0.005
va = 'bottom' if bar.get_height() >= 0 else 'top'
plt.text(bar.get_x() + bar.get_width()/2, y_pos,
f'{improvement:+.3f}', ha='center', va=va, fontsize=8)
# Add summary statistics
avg_improvement = np.mean(improvements)
plt.text(0.02, 0.98, f'Avg Improvement: {avg_improvement:+.3f}',
transform=plt.gca().transAxes, va='top', ha='left',
bbox=dict(boxstyle='round', facecolor=viridis_colors[4], alpha=0.6))
else:
plt.text(0.5, 0.5, 'Unable to calculate improvements', ha='center', va='center', transform=plt.gca().transAxes)
plt.title('Model Improvement by Composer')
except Exception as e:
plt.text(0.5, 0.5, f'Error: {str(e)}', ha='center', va='center', transform=plt.gca().transAxes)
plt.title('Model Improvement by Composer')
def plot_hyperparameter_analysis(best_params, all_results, viridis_colors, env_config):
"""Plot hyperparameter analysis"""
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
# Best parameter values visualization
best_param_text = "\n".join([f"{k}: {v}" for k, v in best_params.items()])
plt.text(0.1, 0.9, f"Best Parameters:\n{best_param_text}",
transform=plt.gca().transAxes, fontsize=12,
bbox=dict(boxstyle='round', facecolor=viridis_colors[5], alpha=0.7))
plt.axis('off')
plt.subplot(1, 2, 2)
# Performance distribution of top configurations
if len(all_results) > 0:
top_scores = [result['val_accuracy'] for result in all_results[:min(10, len(all_results))]]
trial_numbers = [result['trial'] for result in all_results[:min(10, len(all_results))]]
# Use viridis gradient for bars
n_bars = len(top_scores)
bar_colors = sns.color_palette(env_config.color_pallete, n_bars)
bars = plt.bar(range(len(top_scores)), top_scores, alpha=0.8, color=bar_colors)
plt.xlabel('Configuration Rank')
plt.ylabel('Validation Accuracy')
plt.title('Top Hyperparameter Configurations')
plt.xticks(range(len(top_scores)), [f'#{i+1}' for i in range(len(top_scores))])
plt.grid(True, alpha=0.3)
# Add value labels
for bar, score, trial in zip(bars, top_scores, trial_numbers):
plt.text(bar.get_x() + bar.get_width()/2, bar.get_height() + 0.001,
f'{score:.3f}\n(Trial {trial})', ha='center', va='bottom', fontsize=8)
else:
plt.text(0.5, 0.5, 'No tuning results available', ha='center', va='center', transform=plt.gca().transAxes)
plt.tight_layout()
plt.show()
def print_improvement_summary(test_metrics, final_metrics, best_score, all_results, best_params):
"""Print model improvement summary without asterisk separators"""
print("\nMODEL IMPROVEMENT SUMMARY")
print(f"\nOverall Performance Improvement:")
print(f"Accuracy: {final_metrics['accuracy'] - test_metrics['accuracy']:+.4f}")
print(f"Precision: {final_metrics['precision'] - test_metrics['precision']:+.4f}")
print(f"Recall: {final_metrics['recall'] - test_metrics['recall']:+.4f}")
print(f"F1-Score: {final_metrics['f1_score'] - test_metrics['f1_score']:+.4f}")
print(f"\nHyperparameter Tuning Results:")
print(f"Best validation accuracy: {best_score:.4f}")
print(f"Number of configurations tested: {len(all_results)}")
print(f"Best parameters: {best_params}")
# Per-composer improvement analysis
try:
composers = [c for c in TARGET_COMPOSERS if c in test_metrics['classification_report'] and c in final_metrics['classification_report']]
if composers:
print(f"\nPer-Composer F1-Score Analysis:")
print(f"{'Composer':<12} {'Default':<8} {'Tuned':<8} {'Improvement':<12}")
total_improvement = 0
for comp in composers:
default_f1 = test_metrics['classification_report'][comp]['f1-score']
tuned_f1 = final_metrics['classification_report'][comp]['f1-score']
improvement = tuned_f1 - default_f1
total_improvement += improvement
print(f"{comp:<12} {default_f1:.3f} {tuned_f1:.3f} {improvement:+.3f}")
avg_improvement = total_improvement / len(composers)
print(f"{'Average':<12} {'':8} {'':8} {avg_improvement:+.3f}")
# Identify best and worst performing composers
composer_improvements = [(comp, final_metrics['classification_report'][comp]['f1-score'] - test_metrics['classification_report'][comp]['f1-score']) for comp in composers]
composer_improvements.sort(key=lambda x: x[1], reverse=True)
print(f"\nMost improved composer: {composer_improvements[0][0]} ({composer_improvements[0][1]:+.3f})")
print(f"Least improved composer: {composer_improvements[-1][0]} ({composer_improvements[-1][1]:+.3f})")
except Exception as e:
print(f"Could not generate per-composer analysis: {e}")
# Main execution
# Plot training history for tuned model
plot_training_history(final_history, figsize=(18, 6))
# Get viridis color palette
viridis_colors = sns.color_palette(env_config.color_pallete, 8)
composer_colors = dict(zip(TARGET_COMPOSERS, sns.color_palette(env_config.color_pallete, len(TARGET_COMPOSERS))))
# Compare performance with subplots
plt.figure(figsize=(16, 10))
# Subplot 1: Overall metrics comparison
plt.subplot(2, 2, 1)
plot_model_comparison(test_metrics, final_metrics, viridis_colors)
# Subplot 2: Performance by Composer (Default Model)
plt.subplot(2, 2, 2)
plot_composer_performance(test_metrics, composer_colors, 'Default Model: F1-Score by Composer')
# Subplot 3: Performance by Composer (Tuned Model)
plt.subplot(2, 2, 3)
plot_composer_performance(final_metrics, composer_colors, 'Tuned Model: F1-Score by Composer')
# Subplot 4: Improvement Analysis
plt.subplot(2, 2, 4)
plot_improvement_analysis(test_metrics, final_metrics, viridis_colors)
plt.tight_layout()
plt.show()
# Additional analysis: Hyperparameter importance visualization
plot_hyperparameter_analysis(best_params, all_results, viridis_colors, env_config)
# Print summary statistics
print_improvement_summary(test_metrics, final_metrics, best_score, all_results, best_params)



MODEL IMPROVEMENT SUMMARY
Overall Performance Improvement:
Accuracy: -0.0205
Precision: -0.0205
Recall: -0.0205
F1-Score: -0.0205
Hyperparameter Tuning Results:
Best validation accuracy: 0.8471
Number of configurations tested: 4
Best parameters: {'lstm_units': 128, 'cnn_filters': 64, 'dense_units': 512, 'dropout_rate': 0.25, 'learning_rate': 0.001}
Per-Composer F1-Score Analysis:
Composer Default Tuned Improvement
Bach 0.968 0.980 +0.013
Beethoven 0.970 0.928 -0.042
Chopin 0.982 0.965 -0.017
Mozart 0.880 0.821 -0.059
Average -0.026
Most improved composer: Bach (+0.013)
Least improved composer: Mozart (-0.059)
Hyperparameter Tuning & Model Performance Interpretation¶
1. Training Performance with Best Parameters¶
- Final Validation Accuracy: 95.56% (best validation accuracy: 96.57% during training)
- Final Validation Loss: 0.8449 (best validation loss: 0.8405)
- Training completed in 81 epochs out of 100, with early stopping preventing overfitting.
- Accuracy and loss curves show smooth convergence, with validation accuracy closely tracking training accuracy.
2. Hyperparameter Search Overview¶
- Search Space:
lstm_units,cnn_filters,dense_units,dropout_rate,learning_rate - Number of configurations tested: 4
- Best Configuration:
- LSTM units: 128
- CNN filters: 64
- Dense units: 512
- Dropout rate: 0.25
- Learning rate: 0.001
- Best validation accuracy during tuning: 84.71% (lower than the default model’s 96.75% test accuracy)
3. Overall Performance Comparison (Default vs Tuned Model)¶
- Accuracy: Dropped from 0.967 (default) to 0.947 (tuned) → -0.0205
- Precision: Dropped by the same margin (-0.0205)
- Recall: Dropped by the same margin (-0.0205)
- F1-Score: Dropped by the same margin (-0.0205)
- Despite parameter optimization attempts, the tuned model underperformed compared to the default configuration.
4. Per-Composer F1-Score Impact¶
- Bach: Improved from 0.968 to 0.980 (+0.013)
- Beethoven: Dropped from 0.970 to 0.928 (-0.042)
- Chopin: Dropped from 0.982 to 0.965 (-0.017)
- Mozart: Dropped from 0.880 to 0.821 (-0.059)
- Average change: -0.026 (overall decline)
5. Insights & Observations¶
- The default model remains superior overall, suggesting the initial hyperparameters were already close to optimal.
- Improvements were seen only for Bach, but significant drops for Beethoven, Chopin, and especially Mozart outweighed the gains.
- The tuned model's best validation accuracy (84.71%) during tuning suggests that the search space or evaluation setup may require refinement for better results.
6. Recommendations¶
- Reassess the tuning search space to include more aggressive ranges for LSTM units, CNN filters, and learning rates.
- Incorporate class-specific weighting or focal loss during tuning to protect performance for minority classes like Mozart.
- Increase the number of trials to explore a broader parameter landscape.
- Consider using Bayesian optimization or Hyperband for more efficient and targeted hyperparameter search.
While hyperparameter tuning aimed to improve per-class performance and generalization, the results indicate that the original model configuration remains the best for balanced accuracy across all composers. Further tuning should focus on targeted improvements for weaker classes rather than global parameter adjustments.
# Model Prediction and Analysis
print("\nMODEL PREDICTION AND ANALYSIS")
try:
# Sample predictions on test set
print("Making sample predictions...")
# Select random test samples
num_samples = min(10, len(data_splits['y_test_encoded']))
sample_indices = np.random.choice(
len(data_splits['y_test_encoded']),
size=num_samples,
replace=False
)
# Make predictions
X_test_list = [
data_splits['X_test']['musical'],
data_splits['X_test']['harmonic'],
data_splits['X_test']['sequences']
]
y_pred_prob = pipeline.model.predict(X_test_list, verbose=0)
y_pred = np.argmax(y_pred_prob, axis=1)
print("\nSample Predictions Results:")
print(f"{'Index':<6} {'True':<12} {'Predicted':<12} {'Confidence':<12} {'Correct':<8}")
correct_predictions = 0
for idx in sample_indices:
true_label = TARGET_COMPOSERS[data_splits['y_test_encoded'][idx]]
pred_label = TARGET_COMPOSERS[y_pred[idx]]
confidence = y_pred_prob[idx, y_pred[idx]]
is_correct = true_label == pred_label
if is_correct:
correct_predictions += 1
status = "CORRECT" if is_correct else "WRONG"
print(f"{idx:<6} {true_label:<12} {pred_label:<12} {confidence:<12.4f} {status:<8}")
sample_accuracy = correct_predictions / len(sample_indices)
print(f"Sample Accuracy: {correct_predictions}/{len(sample_indices)} ({sample_accuracy:.1%})")
# Detailed analysis for first few samples
print("\nDetailed Top-3 Predictions:")
for i, idx in enumerate(sample_indices[:3]):
true_label = TARGET_COMPOSERS[data_splits['y_test_encoded'][idx]]
# Get top 3 predictions
top_3_idx = np.argsort(y_pred_prob[idx])[-3:][::-1]
print(f"\nSample {idx} (True: {true_label}):")
for j, pred_idx in enumerate(top_3_idx, 1):
composer = TARGET_COMPOSERS[pred_idx]
prob = y_pred_prob[idx, pred_idx]
print(f" {j}. {composer}: {prob:.4f}")
print("\nPrediction analysis completed!")
except Exception as e:
print(f"Error during prediction analysis: {e}")
MODEL PREDICTION AND ANALYSIS Making sample predictions... Sample Predictions Results: Index True Predicted Confidence Correct 267 Chopin Chopin 0.8005 CORRECT 106 Mozart Mozart 0.7683 CORRECT 323 Mozart Mozart 0.7677 CORRECT 552 Beethoven Beethoven 0.8392 CORRECT 395 Bach Bach 0.8416 CORRECT 202 Bach Bach 0.8237 CORRECT 528 Beethoven Beethoven 0.8543 CORRECT 30 Bach Bach 0.7572 CORRECT 44 Beethoven Beethoven 0.5331 CORRECT 162 Chopin Chopin 0.7330 CORRECT Sample Accuracy: 10/10 (100.0%) Detailed Top-3 Predictions: Sample 267 (True: Chopin): 1. Chopin: 0.8005 2. Beethoven: 0.0668 3. Bach: 0.0666 Sample 106 (True: Mozart): 1. Mozart: 0.7683 2. Bach: 0.1273 3. Chopin: 0.0637 Sample 323 (True: Mozart): 1. Mozart: 0.7677 2. Beethoven: 0.1309 3. Chopin: 0.0607 Prediction analysis completed!
Model Prediction & Analysis¶
1. Sample Prediction Results¶
- Total samples evaluated: 10
- Correct predictions: 10
- Sample accuracy: 100%
- All predictions matched the true composer labels, demonstrating strong classification consistency on the sampled data.
2. Confidence Levels¶
- Prediction confidences ranged from 0.5331 (lowest, Beethoven) to 0.8543 (highest, Beethoven).
- Most predictions had confidence above 0.75, indicating the model is generally certain about its classifications.
- Even the lowest-confidence prediction was correct, suggesting robustness against borderline cases.
3. Top-3 Prediction Analysis¶
- For each sample, the true composer consistently appeared as the top prediction.
- The second and third predictions usually belonged to composers with stylistic similarities to the true class, which aligns with expected musical overlaps.
- Example:
- Chopin sample (Index 267): Top-1 confidence at 0.8005, with Beethoven (0.0668) and Bach (0.0666) as secondary predictions.
- Mozart sample (Index 106): Top-1 confidence at 0.7683, followed by Bach and Chopin.
4. Observations¶
- The model demonstrates high confidence and correctness in predicting all sampled cases.
- Secondary predictions suggest the model is capturing meaningful stylistic relationships between composers.
- The consistent ranking of the true class in Top-1 predictions validates strong predictive reliability.
The prediction analysis reinforces that the trained model maintains high precision and confidence in classifying unseen samples. These results further support its readiness for deployment in composer identification tasks.
try:
# Save the tuned model
final_pipeline.save_artifacts(
modelfilepath=MODEL_PATH,
artifacts_filepath=MODEL_ARTIFACTS_PATH,
history_filepath=MODEL_HISTORY_PATH
)
print("Tuned model artifacts saved successfully.")
print(f"Model saved to: {MODEL_PATH}.keras")
print(f"Artifacts saved to: {MODEL_ARTIFACTS_PATH}")
print(f"Training history saved to: {MODEL_HISTORY_PATH}")
except Exception as e:
print(f"Error during hyperparameter tuning: {e}")
Tuned model artifacts saved successfully. Model saved to: data/model/composer_classification_model.keras.keras Artifacts saved to: data/model/composer_classification_model_artifacts.pkl Training history saved to: data/model/composer_classification_model_history.pkl
# streamlit run ./app.py
Deployment Overview¶
Cloud API: Serve the saved
.kerasmodel via FastAPI inside a Docker container. Load weights from cloud storage (S3/GCS/Azure Blob) at startup and expose a/predictendpoint for MIDI/features → composer predictions. Deploy on Cloud Run, AKS, or ECS with autoscaling and GPU/CPU configuration.CI/CD: Automate builds, run inference smoke tests, and promote to staging/prod with cloud secrets management for storage keys and configs.
Streamlit (Community Cloud): Host a GitHub repo with
app.py,requirements.txt, and preprocessing scripts. Use@st.cache_resourceto load the model, allow MIDI uploads, process input, and display top-k predictions with probability charts.Best Practices:
- Store large models in cloud storage, not the repo.
- Validate inputs, limit file size, and manage secrets via Streamlit Secrets or cloud key vaults.
- Optimize inference (batching, float16, thread limits) for cost and performance.
- Model Architecture Enhancements Implement transformer-based attention mechanisms instead of traditional LSTM layers to better capture long-range dependencies in musical sequences and improve handling of variable-length compositions Add multi-scale temporal modeling using dilated convolutions with different dilation rates to capture musical patterns at multiple time scales (note-level, phrase-level, and structural-level)
- Data and Feature Engineering Expand the dataset with targeted data collection for Mozart and Chopin to address the significant class imbalance (Bach: 62.6% vs Chopin: 8.3%) through synthetic data generation or style transfer techniques Implement advanced musical feature extraction including voice separation analysis, motif tracking, and harmonic tension analysis using circle of fifths relationships to capture more nuanced compositional characteristics
- Training and Optimization Apply focal loss and advanced class weighting strategies specifically designed for minority classes to improve performance on underrepresented composers while maintaining overall accuracy Implement curriculum learning starting with clear, unambiguous pieces and gradually introducing more challenging examples to improve model robustness and convergence
- Evaluation and Deployment Develop musically-informed evaluation metrics that weight errors by musical similarity between composers rather than treating all misclassifications equally Create a comprehensive model interpretability framework using attention visualization and SHAP values to understand which musical passages and features drive classification decisions for musicological insights
- Education & Research: Adaptive music tutoring, manuscript attribution, style analysis, large-scale corpus studies.
- Digital Platforms: Style-based playlist curation, composer-specific recommendations, automated metadata tagging.
- Generative AI: Style-aware composition tools, orchestration aids, media score generation.
- Performance & Production: MIDI editing, arrangement assistance, performance feedback, plagiarism detection.
- Cultural Heritage: Interactive exhibits, automated manuscript cataloging, VR/AR classical experiences.
- AI & Wellness: Music information retrieval, cross-cultural analysis, therapeutic music selection.
- Commercial: Content identification, style-based licensing, brand-specific classical compositions.
Bridges musicology and AI to enhance education, discovery, preservation, creativity, and commercial value.
This project developed and deployed a hybrid CNN-LSTM model with multi-head attention and cross-modal fusion for classifying Bach, Beethoven, Chopin, and Mozart from symbolic music data, achieving 96.75% test accuracy with balanced precision, recall, and F1-scores.
Key Achievements¶
- High Performance: Accurate classification with minimal overfitting (2.82% train–validation gap), converging in 74 epochs.
- Advanced Feature Engineering: 45+ music theory-based features capturing harmonic, rhythmic, melodic, and structural nuances.
- Class Imbalance Handling: Targeted augmentation and adaptive class weighting maintained strong per-class F1-scores (0.880–0.982).
- Robust Design: Multi-branch architecture integrating statistical, harmonic, and sequence data via cross-attention.
Technical Contributions¶
- Multi-Modal Processing: Separate CNN, LSTM, and dense branches fused for richer representation.
- Domain-Specific Analyzers: Custom tools for harmony, rhythm, melody, and structure extraction.
- Optimized Training: Mixed precision and efficient pipelines for speed without loss of expressiveness.
Real-World Impact¶
Applicable to educational tools, digital music libraries, and musicological research, providing high-confidence predictions and interpretable stylistic relationships.
Limitations & Future Work¶
- Enhance Mozart classification through data expansion and targeted features.
- Explore synthetic data generation and transformer architectures.
- Extend classification to more composers and periods.
Broader Significance¶
This work bridges AI and musicology, showing that domain expertise combined with deep learning can deliver both technical excellence and cultural insight, offering a model framework for classification tasks in the digital humanities.
- blanderbuss. (n.d.). MIDI Classic Music [Dataset]. Kaggle. https://www.kaggle.com/datasets/blanderbuss/midi-classic-music
- Yamashita, R., Nishio, M., Do, R. K. G., & Togashi, K. (2018). Convolutional neural networks: an overview and application in radiology. Insights into Imaging, 9(4), 611–629. https://doi.org/10.1007/s13244-018-0639-9
- Hochreiter, S., & Schmidhuber, J. (1997). Long Short-Term Memory. Neural Computation, 9(8), 1735–1780. Retrieved from https://arxiv.org/abs/1304.6700
This assistance was used to understand and plan the technical approaches, model training strategies, and algorithm concepts.
- OpenAI. (2025). ChatGPT [Large language model]. OpenAI. https://chat.openai.com/
Streamlit Application¶